DPD-数字预失真
DPD-数字预失真
前言
家人们,今天咱来唠唠通信界的一个超重要 “选手”——数字预失真 DPD(Digital Pre-Distortion),它在通信领域那可是相当有存在感,就像游戏里的神助攻,能让射频放大器变得超厉害!
DPD 是个啥
DPD 这名字听起来有点绕,简单来说,就是让正常的数字信号提前 “变个样”。
“数字” 嘛,说明是在数字的地盘儿搞事情,和模拟域没啥关系;
“预” 就是提前的意思,在射频功率放大器 “开工” 之前就先行动;
“失真” 呢,信号在传输过程中走样了就叫失真,DPD 就是故意让原始信号 “失失真” 。这就好比给信号提前做了个 “变形手术”,专门用来对付功率放大器的那些小脾气。
既然 DPD 是为了对付 PA 的小脾气的,自然在信号处理系统中,DPD 就要放在 PA 的前面。
为啥需要 DPD
这就得吐槽一下射频功率放大器啦!它有个让人头疼的毛病,输入功率加到一定程度,就开始 “耍小性子”,进入非线性区。这时候,输入和输出不再是 “铁哥们”,不再成线性关系。增加输入功率,输出功率却不给力,效率直线下降,信号还失真了。就好比你使劲给车加油,车却跑不起来,还跑偏了。
接收端收到失真信号后,还会继续 “捣乱”,把失真加剧。那咋办呢?
一般有两种办法,要么降低输入信号功率,躲开非线性区这个 “大坑”;要么增加输入信号功率,牺牲点能量换信号不失真。
DPD 就属于后者,它就像个聪明的 “信号整形师”,让原先的信号朝着和功率放大器相反的方向 “变形”,抵消掉功率放大器的非线性影响 。这么一来,输出和输入信号之间的线性关系区间变宽了,功率放大器效率也提升了,不过功耗也增加了点,就当是给效率提升交的 “小电费” 吧。而且用了 DPD,无线基站的效率能大幅提升,能给网络运营商省下不少钱呢!

谁能搞定 DPD?
设备厂家
那些大型设备厂家,像华为、中兴、爱立信、诺基亚、三星,都是 DPD 技术的 “大拿”,自家都有厉害的 DPD 技术,就像有独家秘籍一样。
小厂就有点尴尬啦,大多没有自己的 DPD 技术,毕竟没积累嘛。没办法,只能找学校 “取经”,或者直接买 FPGA 公司提供的 IP core,就像借别人的工具来干活。
芯片厂家
FPGA 芯片厂家可就牛了,不仅能提供高性能的 DPD 解决方案,而且 IP 核参数还能自己调,不用手动一点点定制,省了好多事儿,就像给你一把万能钥匙,直接打开 DPD 的大门,还能提供超小占位面积、低成本的 FPGA 解决方案。
DPD 有什么实现难点?
DPD 想发挥好作用,也不是一帆风顺的。首先,它的数学模型和参数得和功率放大器(PA)完美匹配,PA 要是变了,DPD 的数学模型或参数也得跟着变,就像脚变了,鞋也得换。
随着 5G 时代到来,载波带宽越来越宽,都能达到 800MHz。以前 4G 的 DPD 数学模型在 5G 基站 PA 这儿就 “水土不服” 了,性能根本不达标,所以还得深入研究新的数学模型。
最后,DPD 不管是用 FPGA、CPU 还是 DSP 来实现,都得从实现难度、资源消耗、成本控制、研发周期等多方面综合考虑,这里面的技术门道可多了,一般人还真搞不定。
功率放大器的模型是什么样?
“宽带” 功放线性区数学模型
所谓 “宽带”,就是信号带宽超宽,啥频率都能在功率放大器里畅通无阻。假设输入是 IQ 调制信号,线性区模型就是输出和输入是简单的倍数关系。经过功率放大器后,信号频谱不变,幅度还放大了,就像给信号打了一针 “放大剂”。
“宽带” 功放非线性区数学模型
到了非线性区,情况就复杂了。可以用幂指数函数或者幂级数函数来描述。
幂指数函数的图像如下:
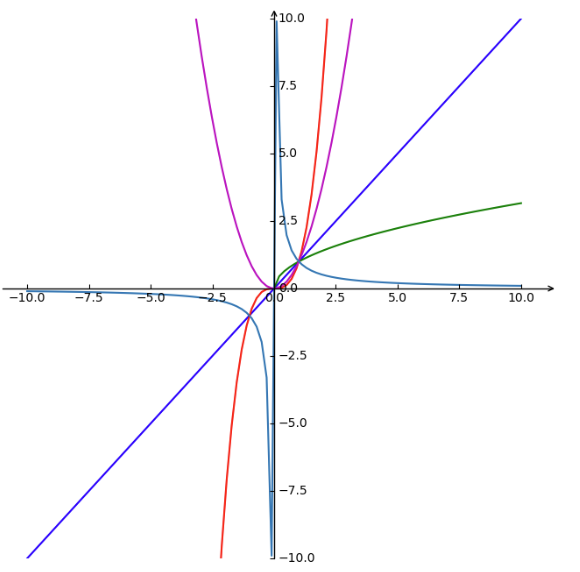
幂级数函数是用来模拟非线性特性的
拿幂级数函数来说,它适合模拟无记忆的弱非线性系统。
上面的公式被称为幂级数,其中$x{0}$为常数,$a{0},a{1},…a{n}$称为幂级数的系数。
下面以输出信号为 IQ 调制信号为例,来说明经过功率放大器后会产生很多的谐波分量;
假设 1:输入信号为 IQ 调制信号(双音正弦信号):
假设 2:功率放大器是三阶函数:
则输出信号的频谱为:基波分量 W,二阶谐波分量 2W,三阶谐波分量 3W;
显然,经过功率放大器后,信号有很多的谐波分量,这就会导致信号的失真;
- 产生的非基波频谱分量(二次、三次谐波分量)分走了本该作用在全部基波上的功率,造成了能量的损失;
- 产生的非基波频谱分量(二次、三次谐波分量)落在信号通带、邻带和其他有用通带内,如果不用滤波器加以滤除,则会对有用信号产生干扰;
- 如果产生谐波分量正好落在信号带宽内,这就无法滤除,产生无法消除的信号干扰;
因此,如果功率放大器在非线性区对高频信号进行放大,损失能量是小事,最麻烦的问题是,会产生谐波干扰信号;
因此,要尽量避免功率放大器对输入信号进行非线性放大,要尽量对信号进行线性放大。
那么可能会有人说,直接让 PA 工作在线性区不就行了吗?实际的通信系统中会面临如下问题:
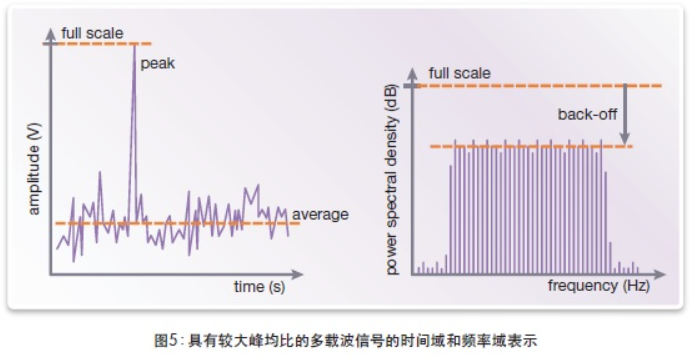
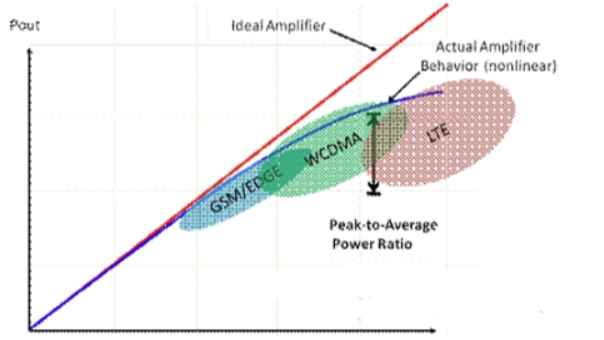
- 信号的幅度变化较大,峰均比(信号峰值与信号均值的比值)比较高,这就意味着即使信号均值落在线性区,信号的峰值也有可能落在非线性区;
- 如果信号峰值和均值都落在线性区,这功率放大器的利用率就很低,大部分时间工作在低功率区,对功率放大器是很大的浪费,功率放大器的线性区间越宽,价格越贵,并且价格相差很大;
- 移动通信系统中,要增加信号的覆盖区,就需要增大发射功率;
因此,无论是从成本,还是实际部署的角度考虑,都期望尽可能让输入信号的功率,工作在接近非线性区附近。
有了这些原因,才会有工程师想,能不能在 PA 之前,先对原始的输入信号$X(t)$进行预处理,得到$Z(t)$,使得功率放大器的输入信号$Z(t)$工作在非线性区,输出信号$Y(t)$与$X(t)$之间还是线性关系呢?
这就是数字预失真 DPD 和削峰 CFR;其中 CFR 的作用是降低信号的峰均比;
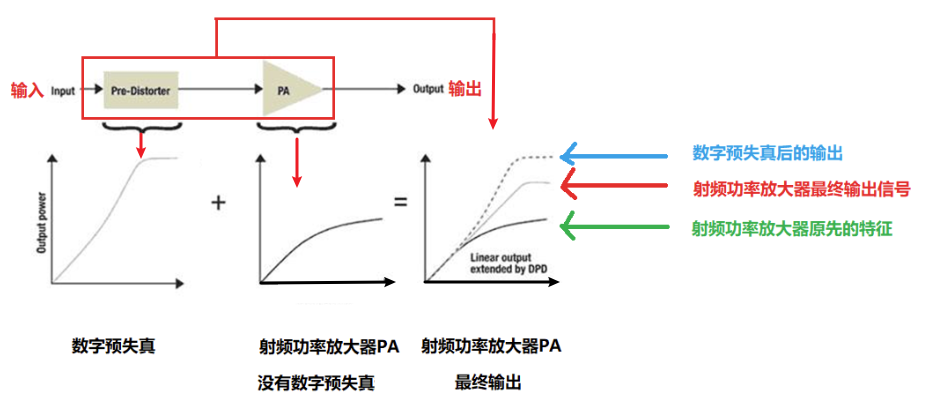
这样带来两个好处:
- 虽然 PA 工作在非线性区,但是如果 DPD+PA,从整体来看,PA 的输出信号和 DPD 的输入信号之间还是线性关系,没有导致输入信号失真;
- 从逻辑上看,在不改变功率放大器的情况下,增大了功率放大器的线性区间;
“带限” 系统的 Volterra 级数模型
实际系统大多是 “带限” 系统,带宽有限制,DAC 对带宽影响很大。带宽增加,不仅会带来记忆效应,对 ADC 要求也更高。“带限” 系统只关心载带和邻带信号,数学模型是 Volterra 级数模型,不同阶数的非线性多项式对应不同带宽的信号非线性分量。为了让建模更准,还得在传统模型里加带限函数。
下图是 DPD 结构的一个示意图
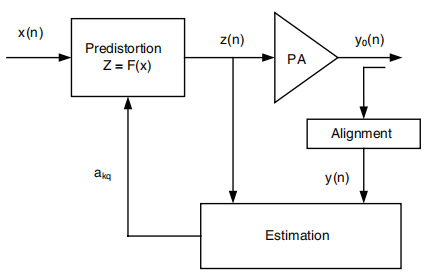
我们使用 Volterra 级数模型对 PA 进行建模的话,可以同时考虑到非线性和记忆效应;
其中 K 是多项式级数,Q 是记忆深度。
From Xilinx DPD IP Doc,Xilinx 对于$a_{kq}$的求解
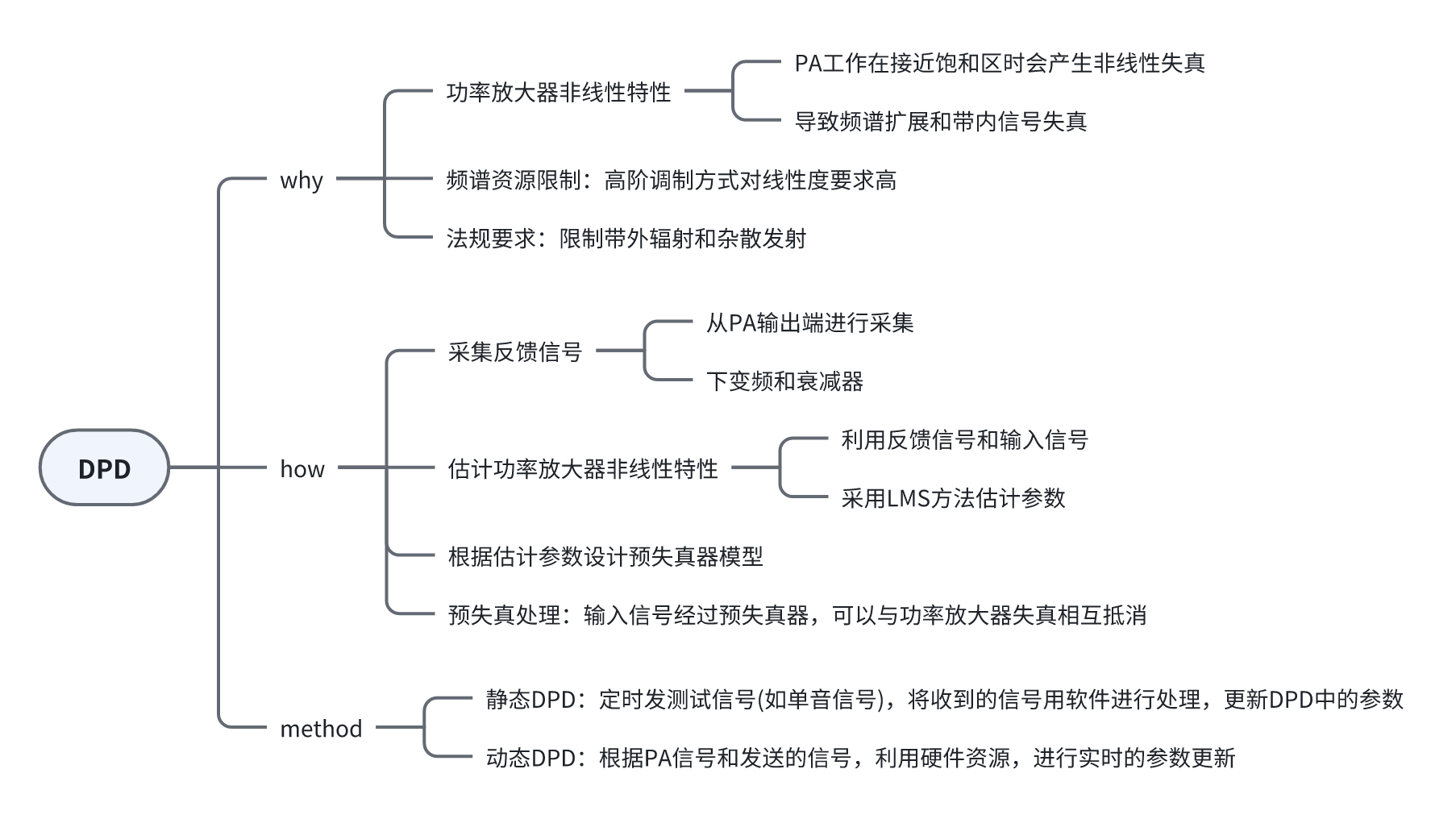
思维导图
 微信
微信 支付宝
支付宝

