DC优化的常用方法
优化是Design Compiler综合中的一个步骤,该步骤根据设计的功能、速度和面积要求,寻找特定目标逻辑库单元的最佳组合。DC提供了一些设计者能够自定义和控制优化的选项,本文将讨论这些选项。
DC的优化过程需要基于设计者对Design的约束,其中约束又分为两类,Design Rule Constraint(DRC)和Optimization Constraint,其中DRC的优先级较高(优先保证满足DRC)。
- Design Rule Constraint:Transition,Fanout,Capacitance;
- Optimization Constraint:Timing,Area;
Automatic Ungrouping
DC工具中,使用compile_ultra命令对设计进行编译时,会自动将设计的层次结构打散。Ungrouping就是将小模块打散直接合并到大模块中,移除了层次结构的边界可以让DC工具“放开手脚”,可以通过减少逻辑级数来改善时序,并通过逻辑共享来降低面积。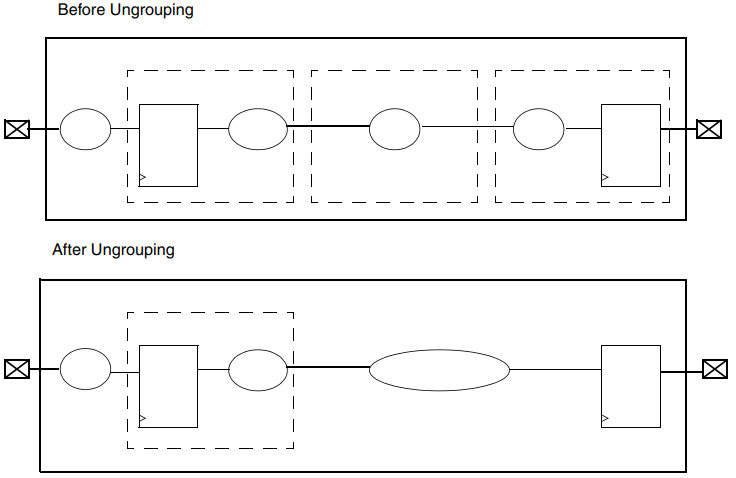
在Ungrouping时,部分小模块会在接口上进行一些时序约束,如multicycle或false path等。在对模块进行Ungrouping时,DC会对这些约束进行保留,将其重新分配给相邻的仍存在的引脚。
对于设计者不想进行Ungrouping的模块,可以对该模块进行属性约束:dont_touch,size_only,set_ungroup等。
High-Level Optimizations and Datapath Optimization
在数据路径的优化阶段,DC会根据时序和面积的约束,对资源进行合理的分配与共享。资源共享是指对多个操作使用同一硬件组件,通常可以减少面积。其他的优化包括算子优化以及通用的运算符共享在此阶段也会进行。
DC的算子优化其实就是使用DC自带的DesignWare库对算子进行高性能映射,可以选择Area优先或者Speed优先,需要额外的licence,这里不再详述。
High-Level Optimizations
DC工具还提供优化树延迟和算子化简的优化手段。举例来说,表达式a+b+c+d描述的是一个3级级联加法器,DC可以对计算的顺序进行优化,变成(a+b)+(c+d),这样可以提高电路速度(2级级联加法器)。算子化简由compile_ultra进行提供,有以下的化简案例:“(a+b-a) => a”,“(aX3X5) => (aX15)”;
Resource Sharing
资源共享减少了HDL中实现加法(+)等操作符所需的硬件数量。如果每个+操作符都构造一个加法器,则会大大增加设计的面积。有两种类型的资源共享:公共子表达式消除和互斥操作的共享。
为理解公共子表达式消除类型的资源共享,以下例进行说明:
1 | // Original RTL |
上述优化方式将比较器由2个降低到1个,降低了面积。DC默认会将下列的操作符进行上述资源共享操作:比较符(=, <, >, <=, >=, !=),移位符(<<, >>, <<<, >>>),算术运算(+, -, x, /, **, %)。
此外,使用compile_ultra进行编译时,工具会自动识别公共子表达式,无需以相同的顺序对表达式进行书写。比如在表达式“A+B+C”和“B+A+D”中,”A+B”和“B+A”被识别为公共子表达式。
另外,DC工具既可以共享公共子表达式,也可以根据约束进行反向共享。以下面的表达式为例,Z1<=A+B+C,Z2<=B+C+D,各信号的arrive time为A<B<D<C。下图展示了DC会根据约束决定资源共享或是反向共享。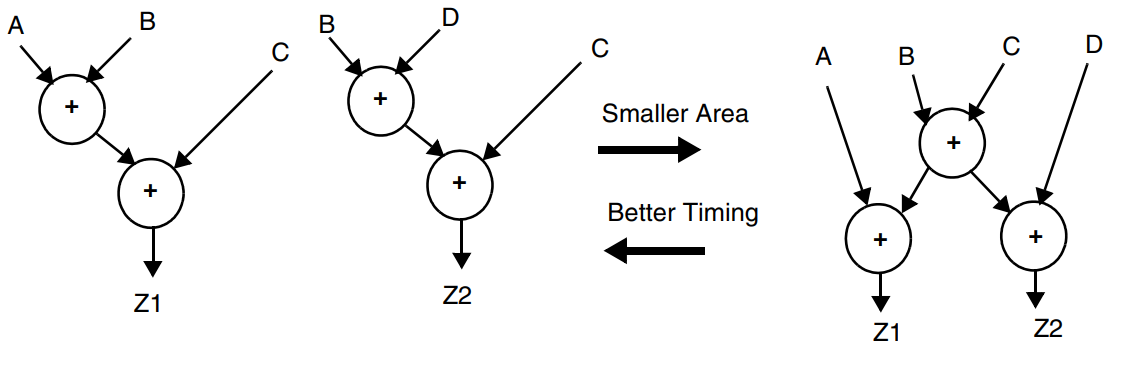
下面介绍共享互斥操作,互斥在这里的含义就是操作不会被同时执行。下面的例子可以更好地帮助理解:
1 | module resources(A,B,C,SEL); |
使用资源共享后的综合结果如下: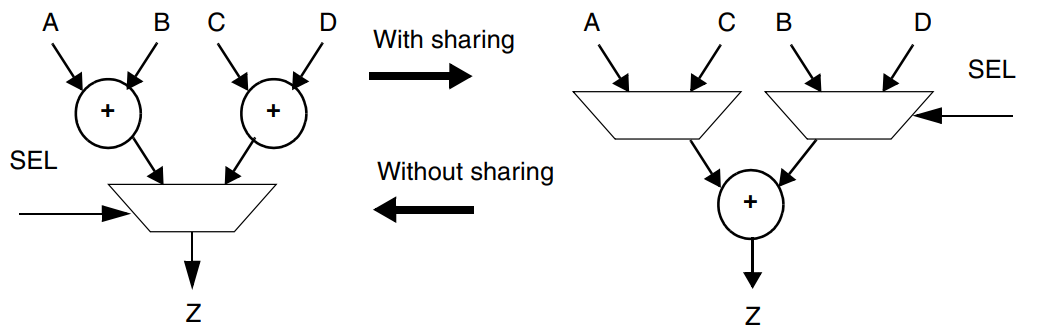
与公共子表达式共享类似,DC会根据时序约束确定是共享还是反向共享。例如,当SEL信号到达较晚且,共享加法器会使QoR(Quality of Results)变差时,DC就不会共享加法器。
Datapath Optimization
DC对Datapath的优化主要通过以下手段:
- 使用Design Ware库;
- 数据路径提取:如果数据的计算路径上有多级加法,可以使用多个树形结构的CSA(carry-save adders)加法器来提高加法的计算速度。使用该方式时有如下前提:1.各运算单元之间没有其他非算术逻辑;2.无法提取被例化的Design Ware模块;
- 合理使用乘法分配律,如:(a x c + b x c)被优化为(a + b) x c;
- 比较器共享,比如a > b,a < b,a ≤ b会调用同一个减法器;
- 操作数重排序;
Path Group
默认情况下,DC根据时钟对path group进行划分,随后DC根据path group对时序进行收敛,默认是对path group中最差的路径进行优化。因此如果设计存在复杂的时钟或时序要求,用户可以将几条关键路径划分为一个path group,指定DC专注于该组路径的优化。
此外,设计者可以对时钟分组设置权重,权重的值范围为0.0-100.0。例如:
1 | group_path -name group0 -from in1 -to FF1/D -weight 2.5 |
Optimizing near-critical paths
默认情况下,DC只优化同一path group内的关键路径,即slack最差的路径。如果在关键路径附近指定一个范围,那么DC就会优化指定范围之内的所有路径。若指定范围较大,会增大DC运行时间,因此一般情况该范围设定为时钟周期的10%。例如:
1 | set_critical_range 3.0 $current_design |
Perform high-effort compile
High-effort compile能够使DC更加努力地达到约束目标,该选项在关键路径上进行重新综合,同时对关键路径周围的逻辑进行了restructure和remap。
restructure主要目的是重新组织和优化设计的逻辑结构,以改进性能、功耗、面积或其他关键指标。以一个32bit的加法器为例说明restructure:在restructure优化前,电路采用传统的级联加法器结构,逻辑门按顺序连接,逻辑的排列和布局可能不是最优的,导致延迟较大,功耗较高;在restructure优化后,DC使用更高级的加法器结构,如Carry Look-Ahead Adder(CLA),代替传统结构,并重新组织逻辑,将关键路径上的逻辑门优化排列,以减小延迟。
high-effort的指令有两种:
- compile_ultra附带两个option,-area_high_effort_script是面积优化,-timing_high_effort_script是时序优化。
- compile附带一个option,
map_effort -high
Perform high-effort incremental compile
通常使用增量编译可以提高电路优化的性能。如果电路在初次compile之后不满足约束,通过增量编译对不满足时序要求的电路进行门级优化。增量编译会增加编译时间,但是时序收敛的有效方法。为了减少DC运算时间,可将那些已经满足时序要求的模块设置为dont_touch属性:
1 | dont_touch noncritical_blocks |
对于那些有很多违例逻辑模块的设计,增量编译通常是最有效的:
1 | compile -map_effort high -incremental_mapping |
Gate-level optimization
DC工具内的门级优化主要是通过选择工艺库中合适的标准单元来对电路进行优化,主要有3个阶段。
Delay optimization
在该阶段,DC通过对关键路径进行遍历来修复Delay的违例。
改善电路的delay主要有以下的思路:
- 打散关键路径上的层次结构,并使能boundary optimization;
- 使用Path Group对关键路径进行分组,并在关键路径附近指定一个范围,那么DC就会优化指定范围之内的所有路径;
- 在探索设计空间阶段,可以给设计的delay更高的优先级,探索设计能达到的最快速度(不一定满足DRC);
- 对于扇出较大的net使用
balance_buffer命令;
在Delay optimization阶段,有下面几种改善电路delay的方式:upsizing, load isolation and splitting.
“upsize” 是一种优化技术,旨在通过增大某些逻辑门的规模来提高电路性能。将电路中的某些标准逻辑门替换成面积更大的逻辑门可以增强逻辑门的驱动能力,从而获得更低的传输延迟,但它会导致面积和功耗的增加,因此使用时需要注意。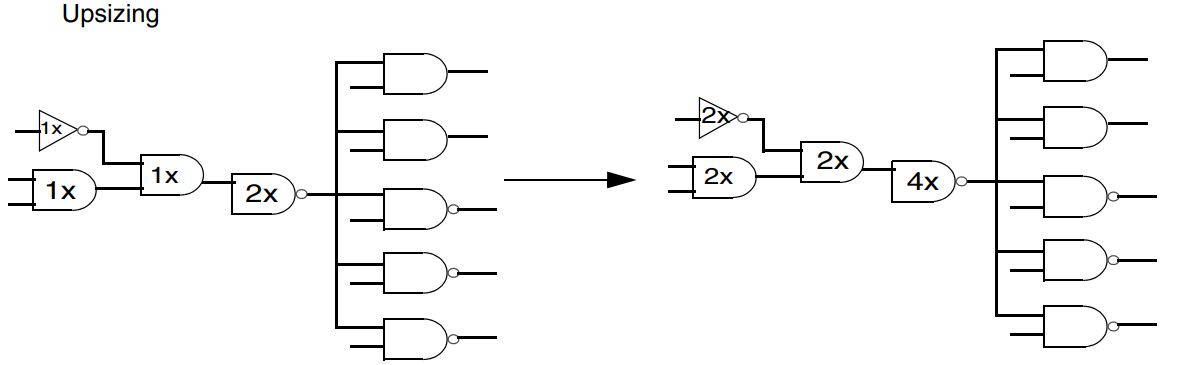
load isolation and splitting旨在减小逻辑门的输出负载,来改善电路的性能指标。主要思想是将逻辑门的输出与输入负载隔离开,以减小输出驱动电流。这可以通过以下方式实现:1. 在输出端插入缓冲器,以减小输出电路的负载电容。这可以降低输出延迟,提高电路的时序性能。同时,缓冲器还可以提供更高的输出驱动能力;2. 重新组织电路逻辑,将一些逻辑元素拆分为多个阶段,以减小每个阶段的输出负载,这通常需要在逻辑层面进行重新设计。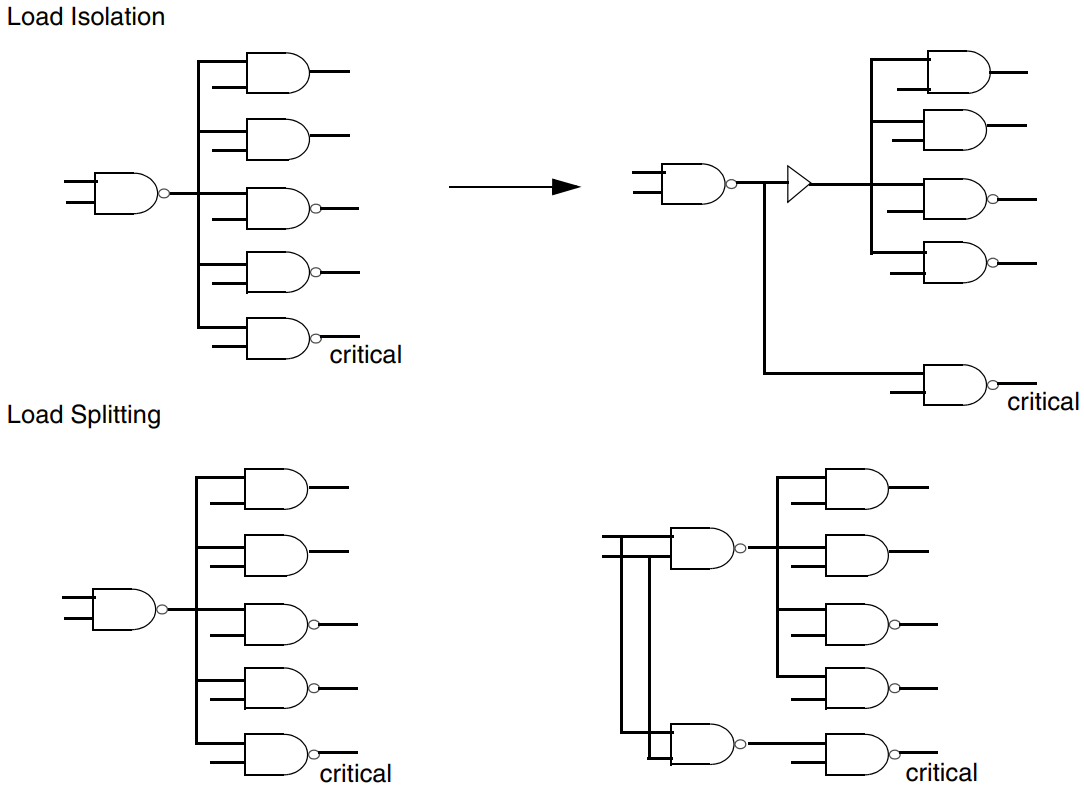
需要注意的是,DC在此阶段已经开始考虑DRC。同样条件下,会选择DRC代价最小的方案。
Design Rule Fixing
- DC主要通过Resize或者插Buffer等方式来满足DRC约束;
- 一般不会影响时序和面积结果,但必要时会导致optimization consrtaints违例;
Area Recovery
- 不会引起DRC和Delay的违例,一般只是对非关键路径进行优化,优化方式包括
Cell DownSize和buffer and inverter cleanup; - 如果没有设置面积约束,那么优化幅度会很小;
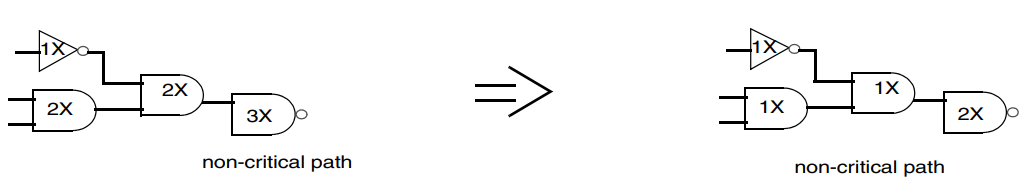
Adaptive Retiming
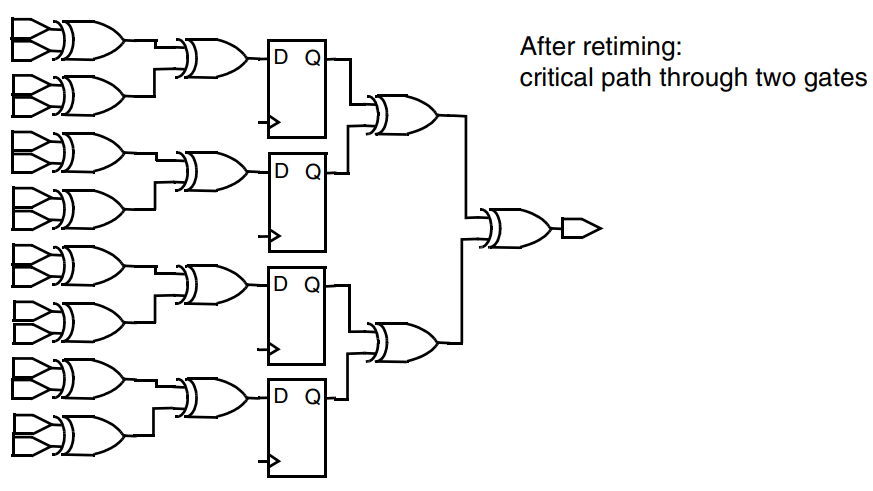
Adaptive Retiming(自适应时序调整)是DC工具中的一种优化技术,旨在调整电路中寄存器的位置以改善电路性能。它可以动态地适应电路中的性能需求,以达到设计目标。这对于高性能数字电路设计非常重要,尤其是在面临时序违规、时序紧迫性和电路性能优化的情况下。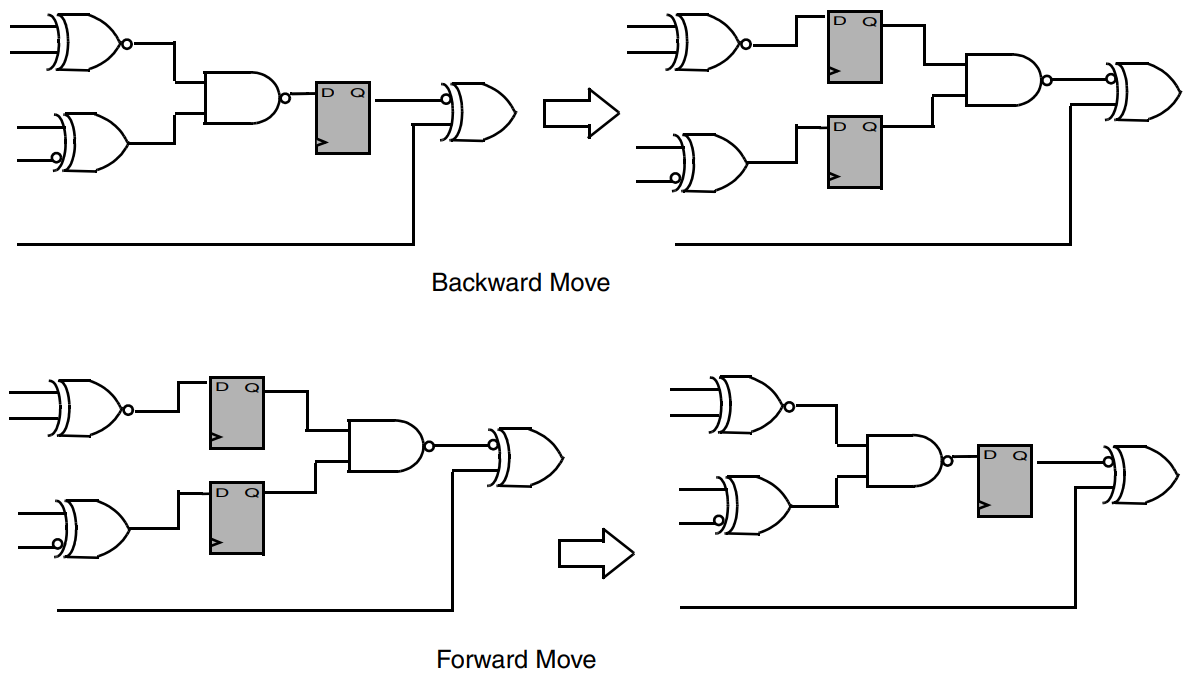
由上图可知,发现设计的流水线划分不平衡时,就可以使用retiming策略。retiming策略有两种,分别是Backward Move和Forward Move,可在时序路径上前后移动寄存器,以提高电路的时序性能。如果没有违例的路径,则可用来减少寄存器的数量。
DC在移动寄存器的优化中,只有对有相同时序约束的寄存器进行调整,如果两个寄存器约束不同,则不能一起移动。
移动后的寄存器在网表中,名字通常带有一个R的前缀,和一个系列号,如R_xxx。
retime策略不能和compile_ultra的以下option一起使用:
- top
- only_design_rule
除此之外其他option都可以同时使用。
“Uniquify” 在数字电路设计工具中的作用是确保设计中的信号名字(如寄存器、信号线等)在整个设计中是唯一的。把例化的多个模块转化成唯一的模块名字,这样优化时可以针对每个模块做优化而不影响其它模块。
Pipelined-Logic Retiming
当设计者在综合之前描述RTL级别的电路时,很难找到最佳的寄存器放置位置并将其编码到HDL中。通过寄存器Retiming,时序逻辑中触发器的位置可以自动调整,以尽可能地平衡各阶段的延迟。
流水线Retiming在输入输出处的逻辑保持不变,因此不用改变TB相关的配置。但是,Retiming会改变设计中寄存器的位置、内容和名称。此时不能使用内部寄存器的输入和输出作为验证的参考点。
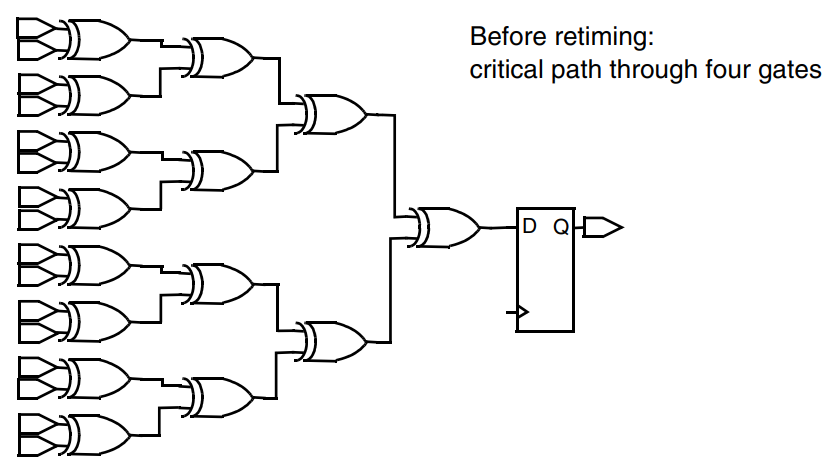
举一个比较夸张的例子,比如我们需要设计一个简单的IP,仅关注输入输出逻辑,验证时也仅看接口信号逻辑。此时IP内部我们可以全部用组合逻辑进行描述,然后进行打拍输出。再启用Pipelined-Logic Retiming对寄存器位置进行重排,如果不满足时序要求则继续增加输出的打拍数目。
Pipelined-Logic Retiming的示意图如下:
Verifying function equivalence
DC中部分优化手段会引起网表和HDL不一致,因此需要使用formality工具进行一致性检查,确认不一致的地方是否由DC优化造成。因此,DC在综合过程中必须生成formality的setup文件(默认为default.svf),给formality进行后续验证。其中可能会导致网表和HDL不一致的原因如下:
- 由ungroup、group、uniquify、rename_design等约束造成部分寄存器、端口名字改变;
- 状态机的优化;
- Retiming策略导致寄存器排布方式与HDL不一致;
- 等效和相反的寄存器被优化,常量寄存器被优化;
- 数据通路优化;
Partitioning for synthesis
把一个设计分割成几个相对简单的部分,称为设计划分(Design Partition)。一般在编写HDL代码之前都需要对所要描述的系统做划分,根据功能或代码量的考虑将一个系统层次化地分成若干个子模块,这些子模块下面再进一步细分,模块(module)就是一个划分的单位。
在运用DC作逻辑综合的过程中,默认情况下各个模块的层次关系是保留着的,保留着的层次关系会对DC综合造成一定的影响。比如在优化的过程中,各个模块的管脚必须保留,这势必影响到模块边界的优化效果。
在HDL编写过程中,一般遵循如下的设计划分原则:
- 避免让一个组合逻辑穿越过多模块;
- 将同步逻辑与异步逻辑剥离;
- 进行寄存输出;
 微信
微信 支付宝
支付宝


