Physical aware synthesis是什么
本文转载自论综合:为什么做physical aware synthesis
如有任何版权问题请联系博主。
前言
工艺的更新给整个半导体行业带来了巨大的挑战,从生产设备、EDA再到芯片设计实现都需要紧跟更新的工艺点亮新技能。下图直观地呈现了从65nm到16/14nm由工艺进步引入的需要额外考虑的因素。
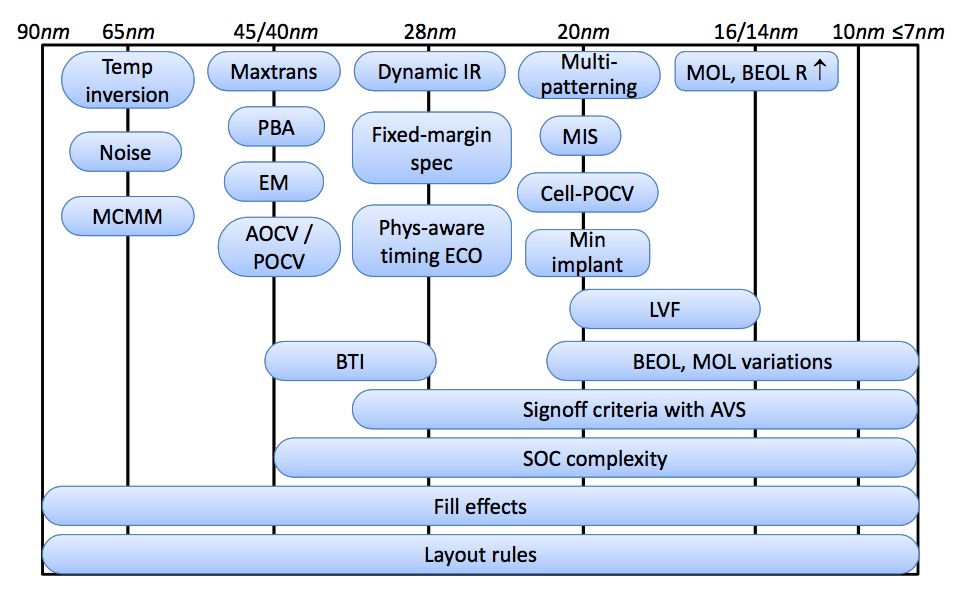
在芯片设计实现流程中,P&R工程师对工艺带来的挑战感受会更直接,综合、STA、DFT 也都有新的方法学的更新,但大都被 EDA 工具严实地包了起来,就拿综合来说,相对于传统综合而言最大的更新莫过于physical aware synthesis。
为什么?
最根本的目的就是减少前后端的迭代次数,前后端迭代次数多的根本原因是前后端的关联度(correlation)差,而correlation需要从timing 和 congestion 两个方面来看:
Timing
综合优化的对象是 timing path,而 Timing path delay = net delay + cell delay,90nm之前 timing path delay 由cell delay 主导,而进入65nm,net delay所占比例日渐增加,进入40nm之后几乎跟cell delay平分秋色。所以从40nm开始physical synthesis 被硅农熟知,因为physical aware synthesis在优化过程中可以看到更精确的net delay。
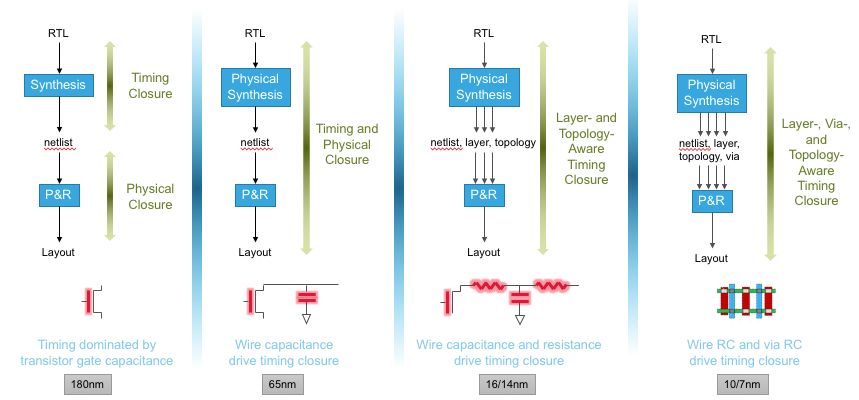
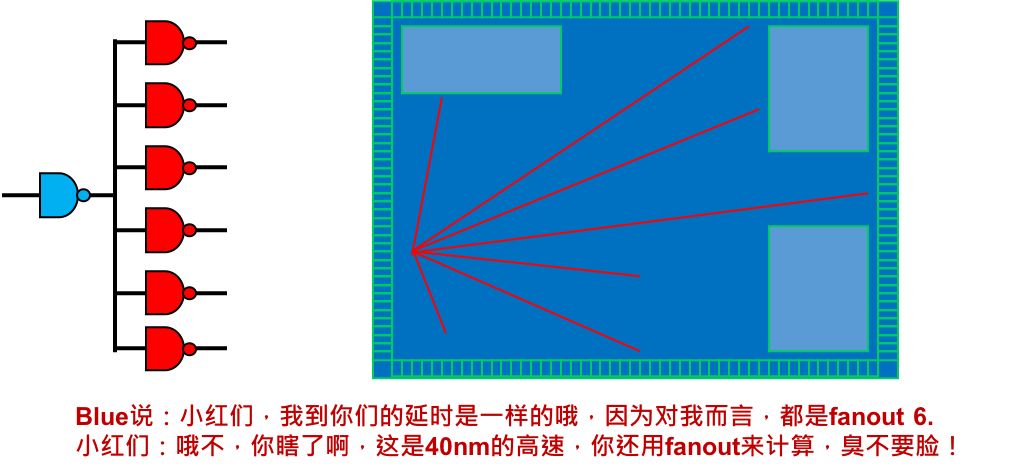
那么为什么logical synthesis不能精确计算net delay呢?这就要回看一下传统综合是如何估算 net delay 的。传统综合俗称logic synthesis,它根据WLM 来估算net delay。WLM (wire load model) 由foundry 提供,WLM通常包括面积系数、电容系数和单位长度的电阻系数,以及一个用于估计net长度的表格,表的index是 fanout,直白地说就是将net的长度拟合成fanout 的函数。
按照WLM来计算,下图中的blue器件到red器件的所有net长度都一样,net delay也一样,而实际上 net 行走的姿势五花八门,根本就不可能一样,缺点显而易见。另一个缺陷是WLM 的单位电容电阻是一个常值,无法模拟不同layer RC 值的差异,而工艺进入16nm 之后,必须要考虑 layer aware 的 net delay。
在40nm甚至28nm,依然有人在用传统的方式来做综合,做法简单粗暴加时钟周期30%甚至更多的过约,这样做是可以cover net delay,但是实在是过犹不及。据统计在一颗芯片里80%以上的线都是短线,为了cover那不到20%的线,付出的代价就是更大的面积及更多的功耗。
那Physical synthesis是如何更精确的计算net delay?要精确计算net delay必须要知道net的行走姿势,而要知道net 的行走姿势必需要知道:它来自哪里?要去向何方?这就需要知道cell 的位置,cell 位置确定了之后,综合工具会做global 绕线,根据global 绕线的结果来估算net delay。cell 位置由placement 确定,所以如今综合工具都集成了 placement 引擎,这也是做 physical synthesis 的关键所在。目前大概有两种做place的方式:
- 做完优化跟mapping之后,再做place,操作对象是std cell;
- 在elaborate 之后优化之初就做place, 即所谓的 early physical, 早期阶段针对module 做palce,mapping之后再以std cell为对象做place;
下图是谷歌上随便找的一张图,只为显示什么是module place, 从Layout 上看每一个颜色对应一个 module。综合工具基本都按 translation + optimization + mapping 三大步来走, 所有结构的选择跟大部分优化的动作都在 optimization 这一步完成,如果可以在 optimization 时就知道 module 的位置信息,优化会更有的放矢会更能『精准打击』,所以 Early physical 十分必要。现在看到的趋势是把更多的物理信息拿到前端来,越早考虑物理信息得到的结果会越好。

结论:physial synthesis根据真实的物理信息,用跟P&R一致的 place 引擎跟 global route 引擎,可以精确估算 net delay,并且是layer aware的。通常physical synthesis 只需过约时钟周期5%~10%即可,用于cover legalization跟detail route 的影响。
Congestion
同样由于工艺进步,集成度提高,单位面积上要走的线骤增,所以 congestion 成了一个从RTL 设计就要开始关注的问题,否则到了绕线的时候绕不通,前面所做的一切都成了无用功。很显然,logical 综合是无法考虑 congestion 的,要在综合阶段做congestion优化必须要 physical synthesis.
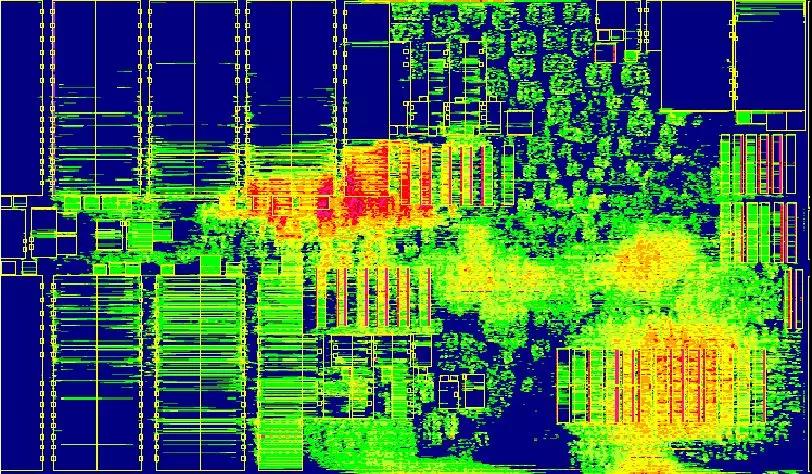
其实不论PPA还是congestion主导决定权都在进实现之前,架构算法设计,才是真正决定一切的『权贵』,所以才说实现是个没有灵魂的工种,只要按着 设计/EDA/foundry 定的规则往下走就可以,切忌的就是『发挥』。
对于congestion,综合工具能做的基本只有两件事:选结构跟推cell。至于选结构,一个例子就是把一个大MUX 拆成多级MUX用于解congestion。推cell这一点完全依赖于EDA 工具,如果你不知道如何做,那就找AE要变量或 option 让工具在综合做place时将 congestion 严重区域的cell推散。除此之外,还有一点可以人为干预,禁用或让工具少用size 小的复杂cell。
要特别说明一点,在16nm之后,layer的影响特别大,所以综合用的DEF一定要有special net 部分,也就是你的power plan,让工具在综合时清楚地知道哪些layer的绕线资源已经被占用。
Reference
 微信
微信 支付宝
支付宝