NVDLA阅读笔记
NVDLA阅读笔记
Unit Description
System Architecture
NVDLA作为深度学习加速器可以集成在SoC中作为一个协处理器;
NVDLA有许多数据处理Engine,各Engine都是独立的且可以自由配置,比如不需要池化的网络可以移除Planar Data Processor,各Engine的调度操作可以委托给Microcontroller或者CPU;其中用Microcontroller来调度的方式称为“headed” implementation,用CPU来调度的方式称为“headless” implementation;
图中左边的框图展示了“headless” implementation的示例,是一个小型的NVDLA系统,成本较低;右边的框图展示了“headed” implementation的示例,是一个大型的NVDLA系统,主要是添加了Microcontroller和高带宽的SRAM,适合于高性能的物联网设备。
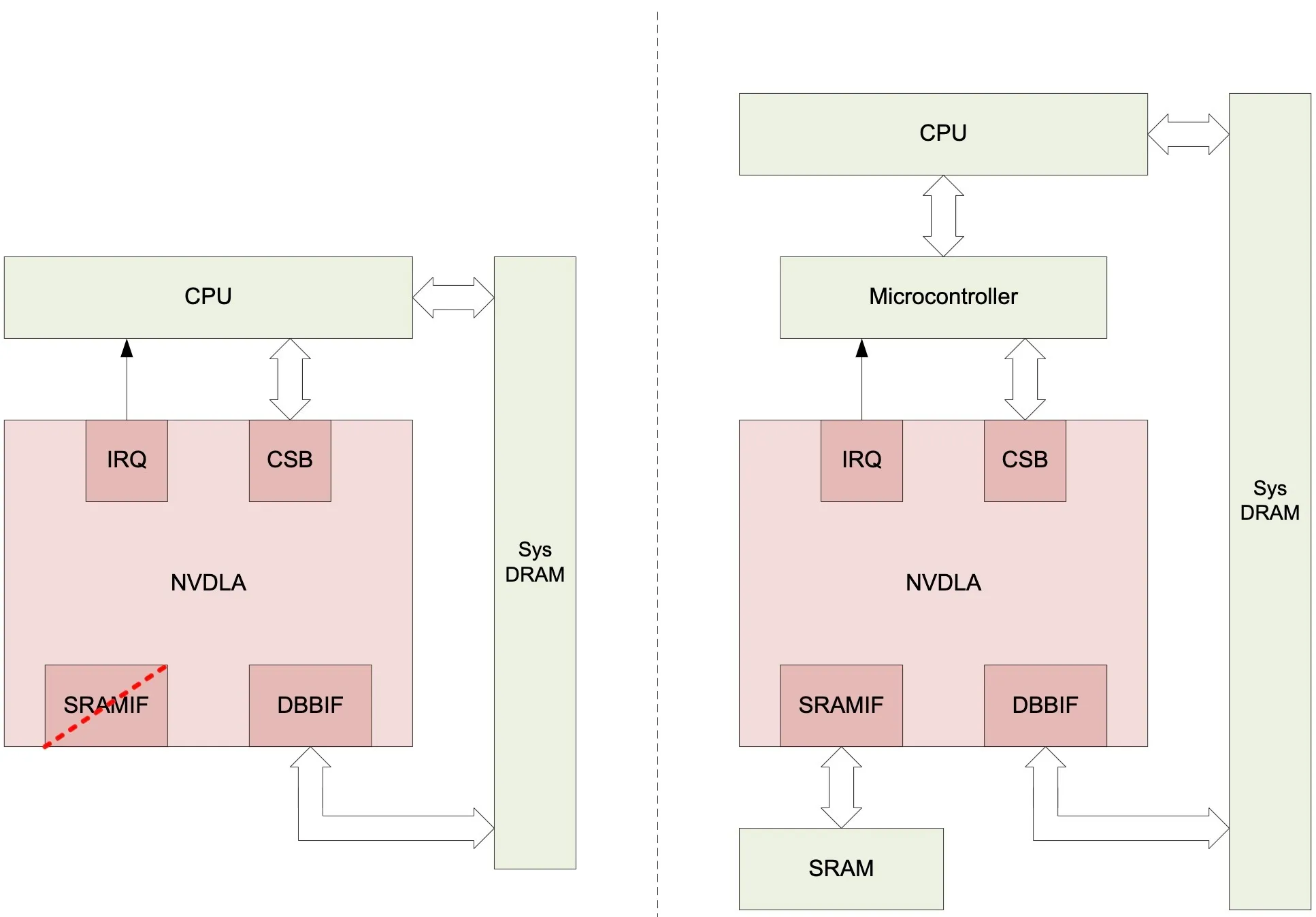
NVDLA主要有4个接口,其中SRAMIF是可选项;
- CSB(Configuration Space Bus):这个接口是一个同步、低带宽、低功耗的32位控制总线,主要用来访问NVDLA的配置寄存器;
- IRQ(Interrupt Request):当NVDLA中的任务完成或者发生错误时会将中断线进行置位;
- DBB(Data Backbone Interface):DBB接口连接NVDLA和片外的DRAM,与AXI接口类似,是高速、高度可配置的数据总线,可以根据系统的要求发出不同大小的读写请求;
- SRAMIF(SRAM Interface):DBB接口还有一个可选的接口,在设计上与DBB接口相同,目的在于结合片上的SRAM来提供更高的数据吞吐量以及更低的访问延迟;
DLA Core Architecture
DLA的结构框图如图所示;内部主要有两个接口模块,其中Configuration Interface用于访问NVDLA的配置寄存器,Memory Interface用于读写特征数据、权重、像素数据等;
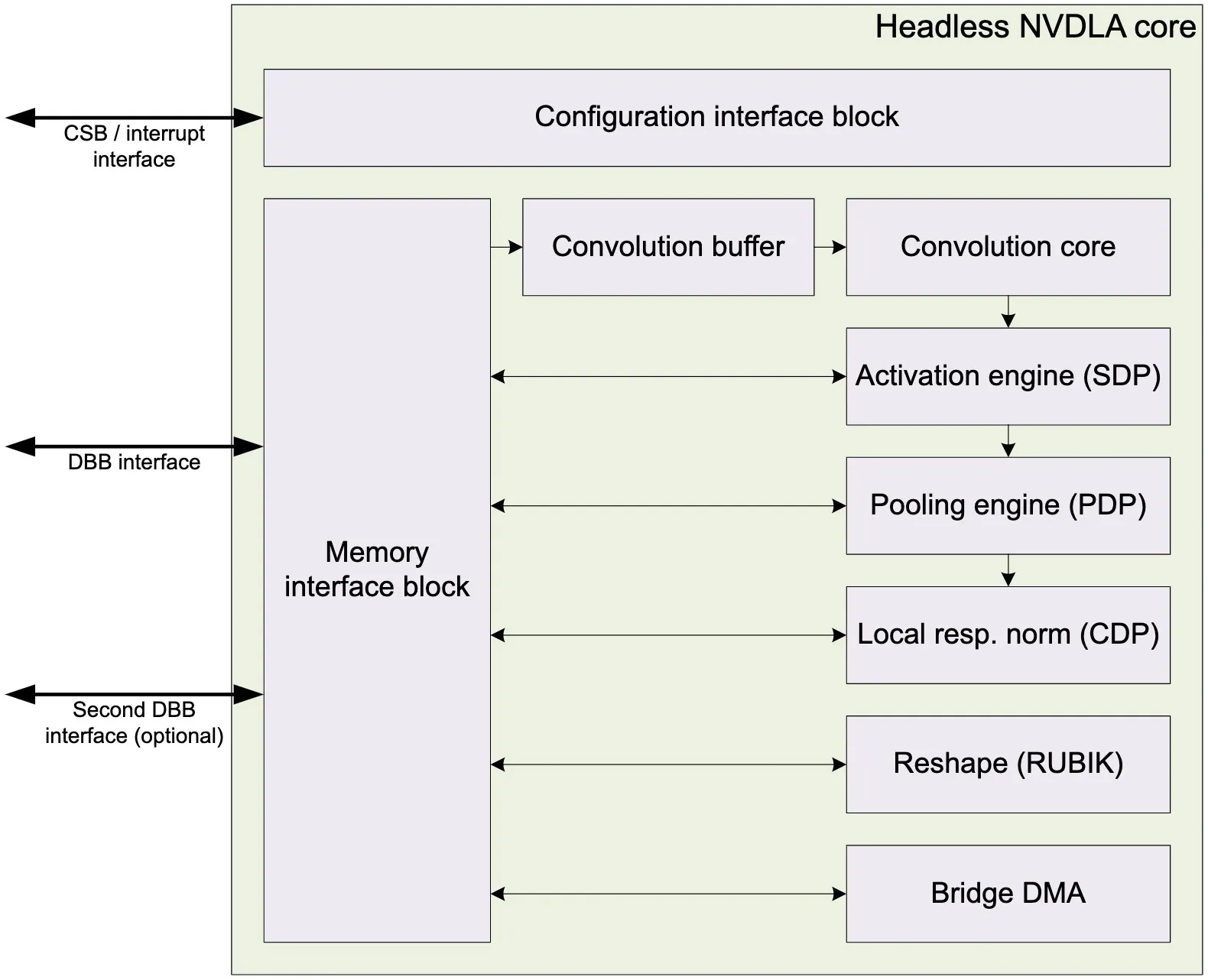
Convolution buffer主要用于缓存像素数据、特征数据、权重数据等,供卷积核中的卷积序列控制器模块读取;Convolution core主要完成卷积中的乘加运算;SDP主要负责对单个数据执行后处理操作,包括bias加法、ReLU、Sigmoid、双曲正切、BN、逐元素操作等;PDP是平面数据处理器,主要完成池化相关的操作;CDP主要在通道方向上执行操作,旨在解决局部响应归一化层;RUBIK模块的功能与BDMA类似,它在不进行任何数据计算的情况下转换数据的映射格式,因为它的功能是变换特征数据立方体的尺寸,所以又被称为魔方单元;BDMA模块在外部DRAM和片上SRAM之间提供了一条移动数据的通道,它有两条独立的路径,一条是将数据从外部DRAM复制/移动到内部SRAM,另一条是将数据从内部SRAM复制/移动到外部DRAM,两条路径不能同时工作;
NVDLA有两种工作模式,独立模式(Independent Mode)和结合模式(Fused Mode)。独立模式下,各Engine分别通过两组数据接口完成各自分配的任务;结合模式可以将Convolution Core、SDP和PDP连接在一起作为一个整体流水线完成分配的任务;
Convolution Pipeline
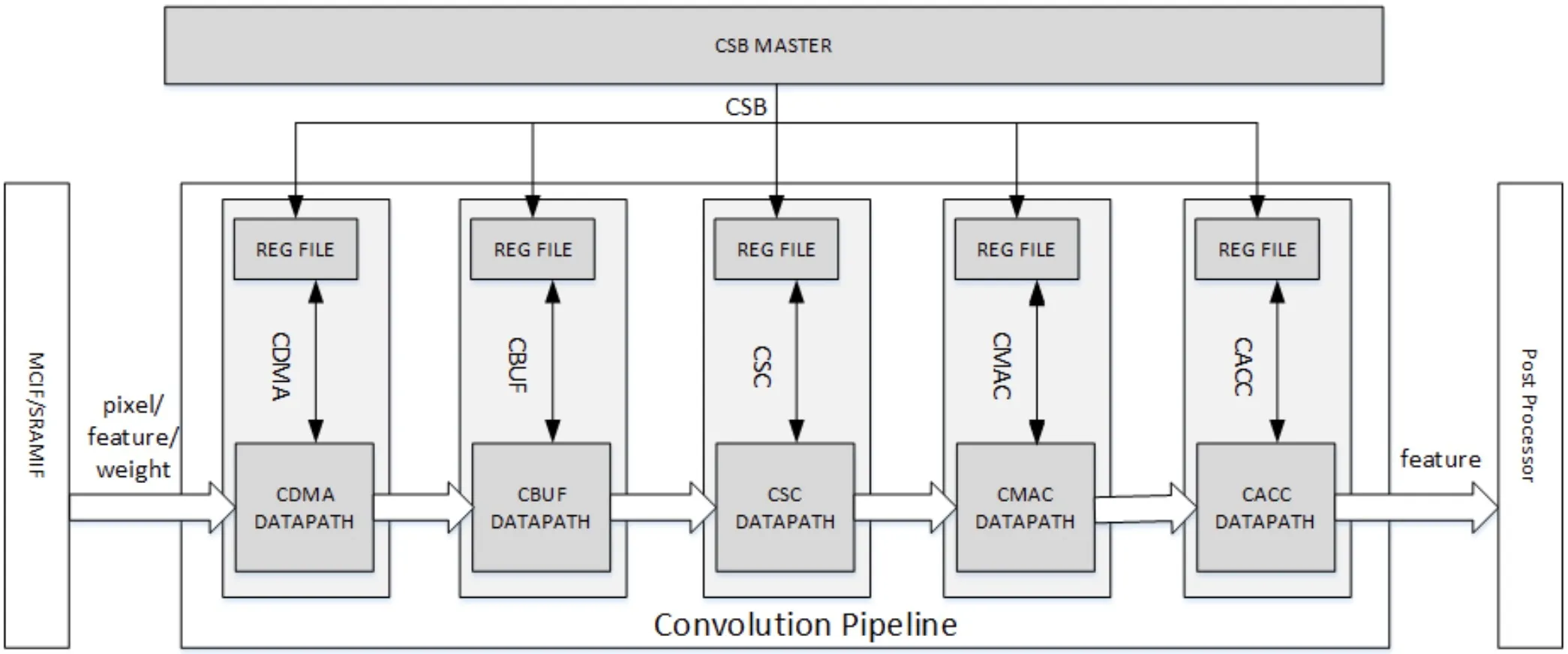
流水线卷积模块是NVDLA的核心逻辑,用于加速卷积算法,同时在卷积流水线中引入了Winograd算法和Multi-batch,提高MAC效率。Convolution Pipeline有五个阶段,分别是Convolution DMA、Convolution Buffer、Convolution Sequence Controller、Convolution MAC和Convolution Accumulator,各阶段都有自己的CSB来接收来自CPU的配置数据。CDMA从SRAM/DRAM中获取数据来进行卷积操作,并按卷积Engine所需的数据顺序存储到CBUF中;CBUF缓存来自CDMA模块的像素、特征和权重等数据,由CSC模块进行读取;CSC模块负责从CBUF加载数据并发送到CMAC单元,它是卷积序列控制的关键模块;CMAC模块从CSC接收输入数据和权重,执行乘法和加法运算,并将结果输出给CACC;CACC模块用于对CMAC模块的部分和进行累加,并在发送给SDP模块前对数据进行舍入操作。
CDMA
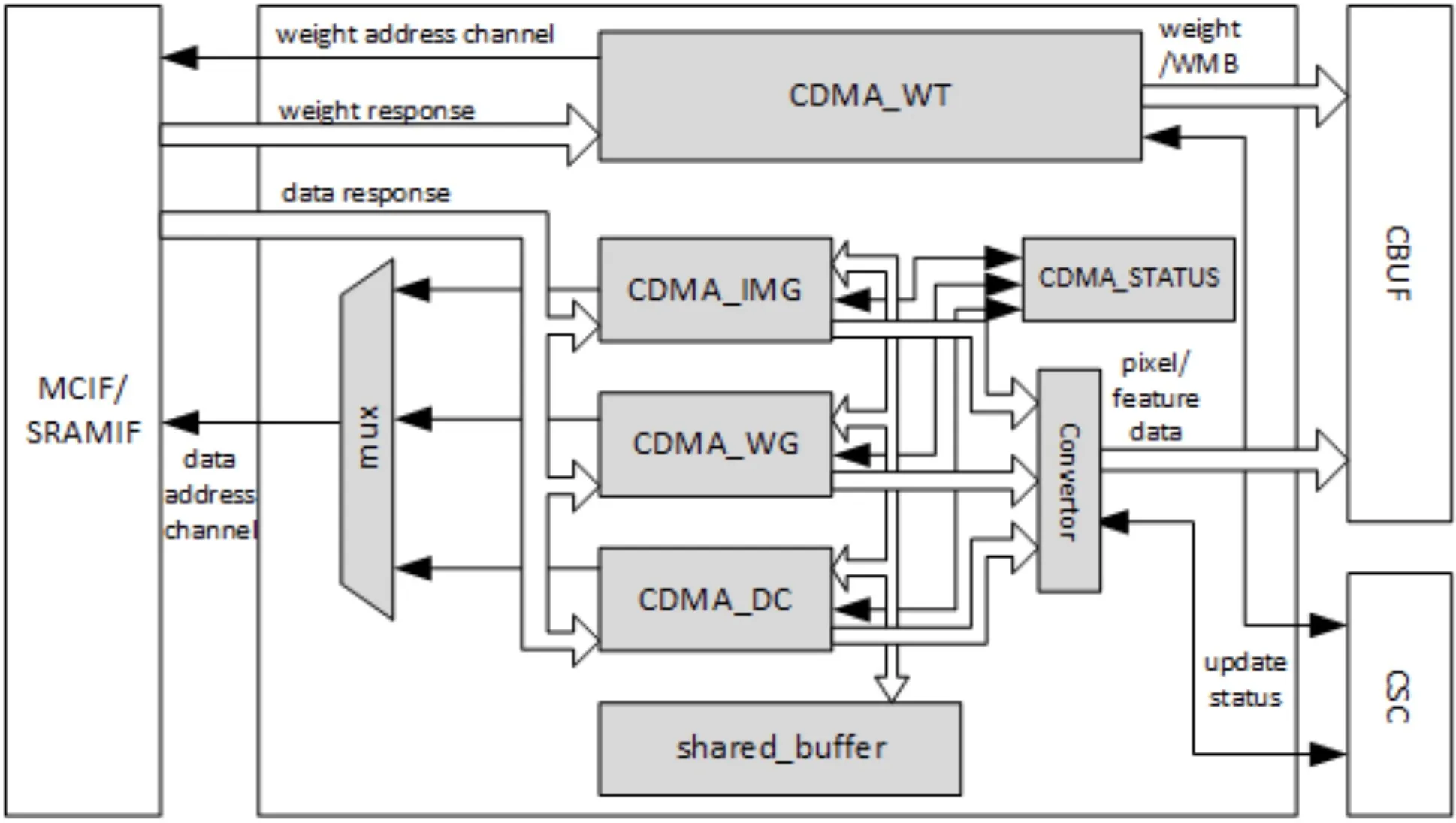
CDMA主要负责从SRAM/DRAM中获取数据来进行卷积操作,读取的数据主要有以下数据类型:
- 像素数据(Pixel Data)
- 特征数据(Feature Data)
- 未压缩/压缩权重数据(Uncompressed/compressed weight)
- WMB(Weight Mask Bit)
- WGS(Weight Group Size)
CDMA主要有两个数据通道,分别是权重读取通道和数据读取通道,CDMA仅发送数据读取的请求。CDMA有三个子模块来获取像素数据或者特征数据来进行卷积,分别是CDMA_IMG(Pixel)、CDMA_WG(Winograd)、CDMA_DC(Direct Convolution)。上述三个子模块的工作步骤类似,区别在于数据存放在CBUF RAM中的格式,任何时候只能有一个子模块被激活来获取像素/特征数据。以CDMA_DC为例介绍一下CDMA的工作流程:
- 检查CBUF的状态,查看是否有空间;
- 进行一个读取事务;
- 在共享缓冲区(Shared_buffer)中缓存特征数据;
- 将特征数据立方体重塑为正确的格式;
- 生成卷积缓冲区(CBUF)的写入地址;
- 将特征数据写入CBUF;
- 更新CDMA_STATUS子模块中CBUF的状态;
CBUF
CBUF模块有16个32KB的Bank,每个Bank由两个512位宽、256深度的双口RAM组成,存储空间共512KB;CBUF缓存来自CDMA的像素、特征、权重和WMB数据,并由CSC模块进行读取;CBUF有两个写端口和三个读端口。
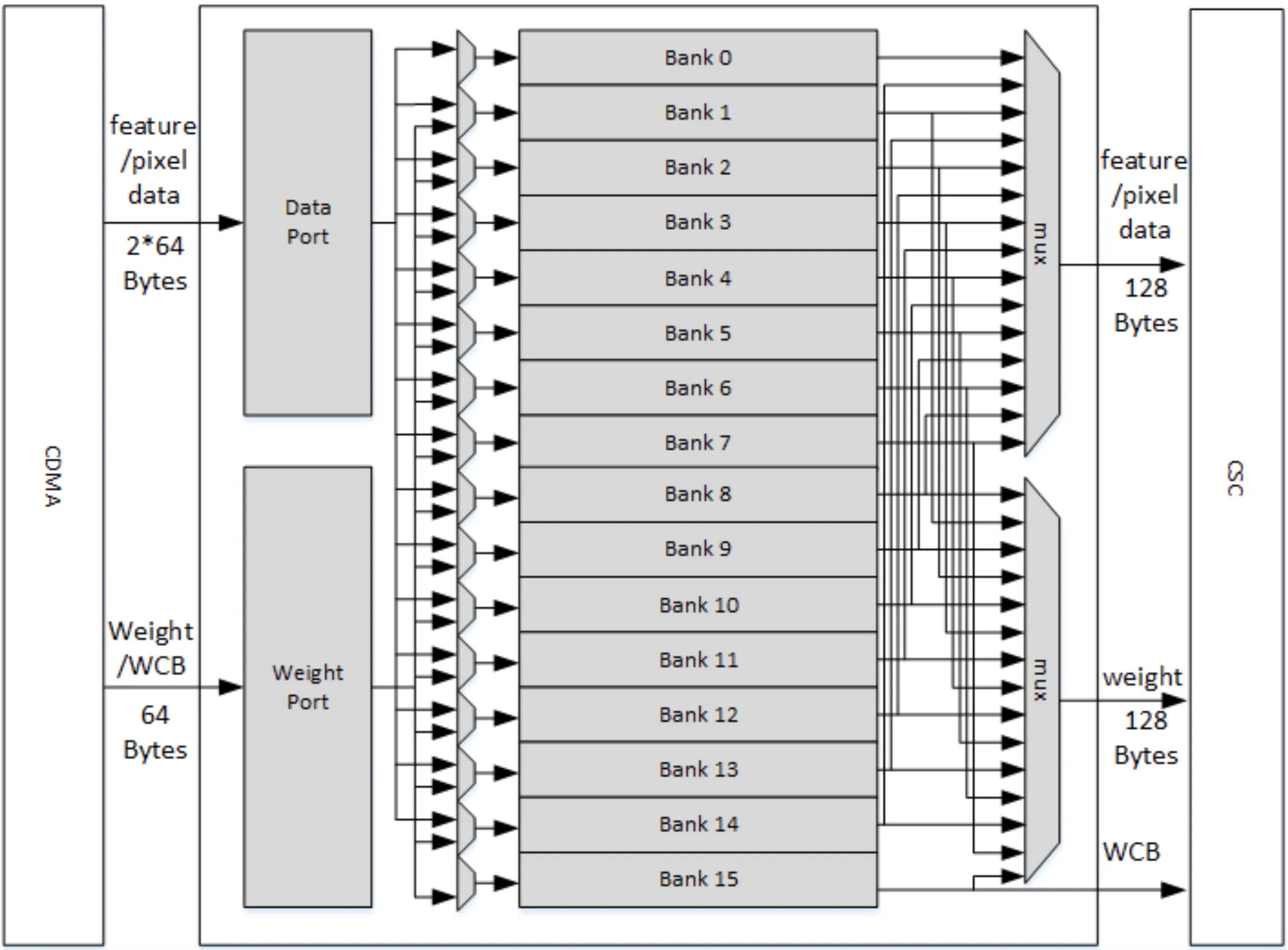
如果权重被压缩,那么Bank15分配给WMB数据,Bank0~14分配给特征、权重进行缓存。如果权重没被压缩,那么特征、权重缓冲区可以使用16个Bank;
每个Bank都是循环缓冲区,新的数据进来时地址都会进行自增,当地址达到最大值后会回到0重新自加;
CSC
卷积序列控制器(CSC)负责从CBUF加载输入特征数据、像素数据和权重数据,并将其发送到CMAC单元,主要包含三个模块:CSC_SG、CSC_WL和CSC_DL。
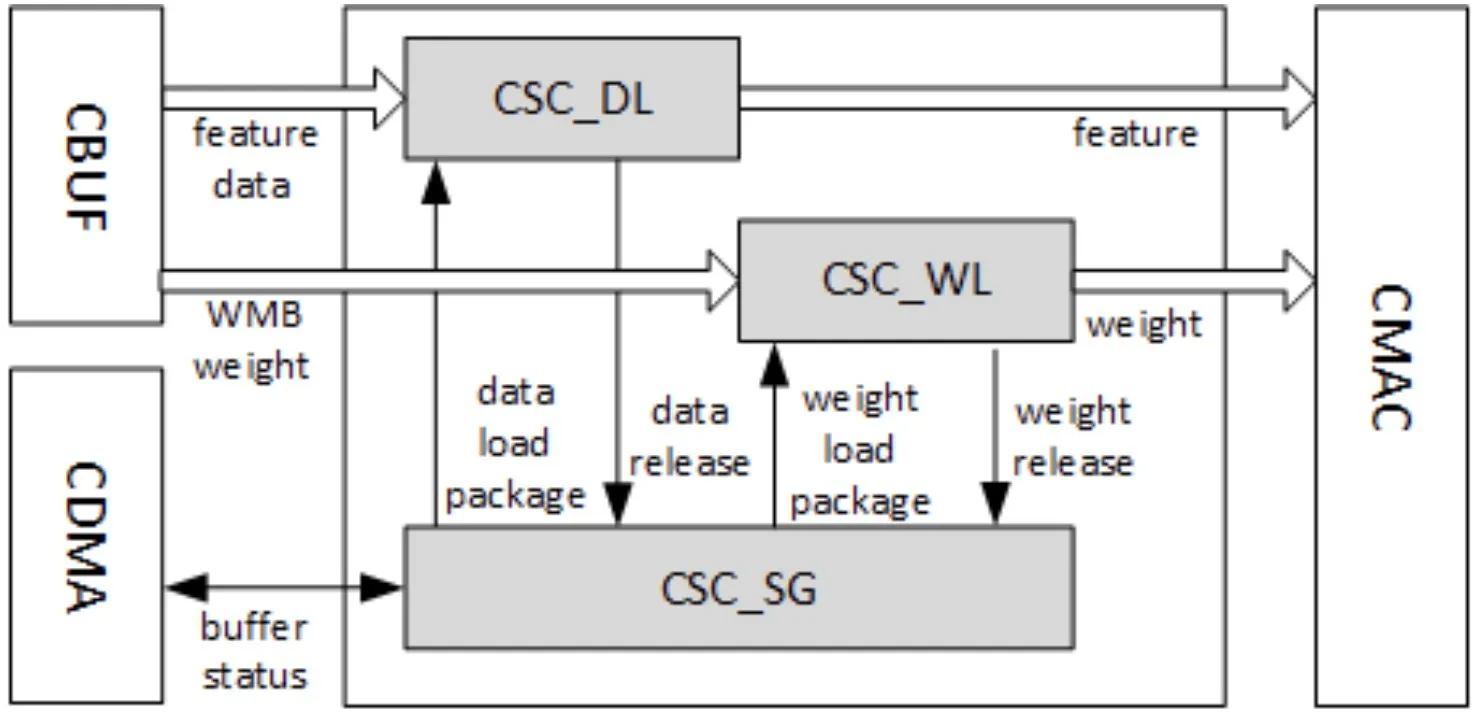
CSC_SG
CSC_SG模块用来生成序列来控制卷积操作,它的工作流程如下:
- 在CBUF中轮询足够的数据和权重;
- 生成一对序列包,包括weight加载包和data加载包,每个包表示一个stripe operation;
- 将两个加载包push到两个FIFO中;
- 两个用于weight和feature/image的计数器都是向下计数;//计数器的作用?
- 当计数器达到零时,检查来自CACC的信号是否有任何back pressure;
- 如果所有条件都准备就绪,就将weight和data包发送给CSC_WL和CSC_DL;
CSC_DL
CSC_DL(Data loader)负责执行feature/image加载序列的逻辑,他从CSC_SG接收包,从CBUF加载feature/image data,并将其发送到CMAC;且它还维护CBUF的状态,并与CDMA通信以保持状态最新。对于Winograd模式,它还执行预加法来转换输入数据;
以DC mode为例说明CSC_DL的工作流程:
- 每个Atomic Operation,DL从CBUF读取一个data atom,并发送给CMAC;
- 每个Stripe Operation,DL从CBUF读取16~32个data atom,并发送给CMAC;
- 每个Block Operation,DL重复(weight_height*weight_width)次stripe operation,从CBUF读取对应的data atom,并发送给CMAC;
- 每次Channel Operation,DL重复C/64次block Operation,从CBUF读取对应的data atom,并发送给CMAC;
- 每个Group Operation,DL遍历整个feature map,重复(data_width*data_height)/(16~32)次channel operation,并发送给CMAC;
- DL重复kernel_num/(16~32)次group operation,每次的data都是相同的;
注:16 or 32取决于数据精度。
CSC_WL
CSC_WL(Weight loader)执行weight加载序列的逻辑,它从CSC_SG接收包,从CBUF加载weight,并进行必要的解压缩并将其发送到CMAC。它帮助维护权重缓冲区状态,并与CDMA_WT通信,来使状态及时更新。
以DC mode为例说明CSC_WL的工作流程:
- 每个atomic operation,WL不需要操作;
- 每个stripe operation,WL从CBUF读取1个group的16/32个weight atom,并发送给CMAC;
- 每个block operation,WL重复(weight_height*weight_width)次stripe operation,从CBUF读取对应的weight atom,并发送给CMAC;
- 每个channel operation,WL重复C/64次block operation,从CBUF读取对应的weight atom,并发送给CMAC;(tips:64=128byte/(int16/fp16))
- 每个group operation,WL反复读取同一组group的weight,重复(data_width*data_height)/(16~32)次channel operation,并发送给CMAC;
- WL重复kernel_num/(16~32)次group operation,完成所有kernel group的读取;
CMAC
CMAC(Convolution Multiply Accumulate)模块是流水线卷积操作的一个阶段,它从CSC接收输入数据和权重,进行乘法和加法运算,并将输出结果输出到卷积累加器。当在Winograd模式下工作时,CMAC在输出上执行POA(post addition)将结果转换为标准激活格式。
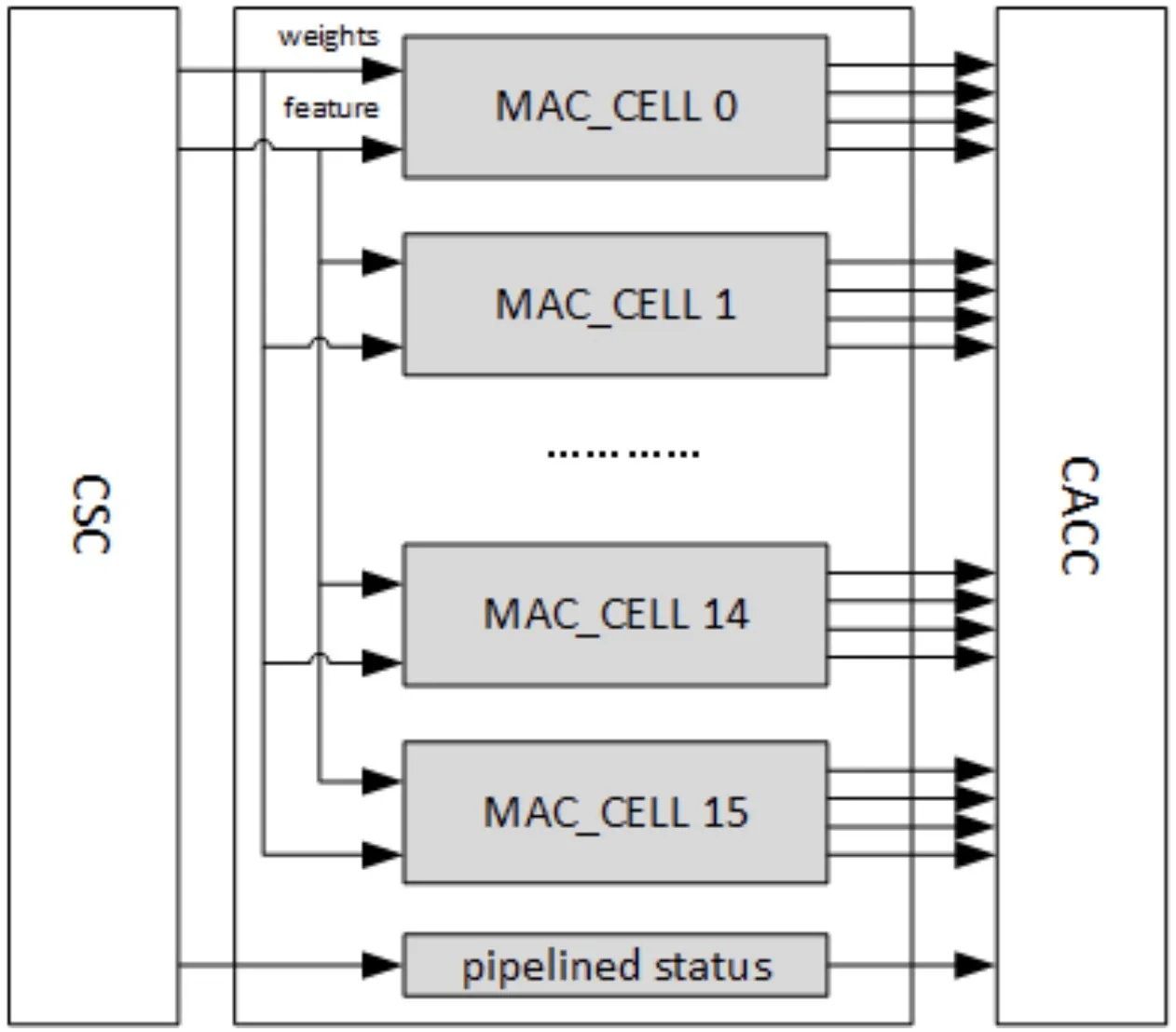
CMAC有16个相同的MAC Cell,每个MAC Cell包含64个用于16bit的16位乘法器,还包含72个16bit的加法器,用于Winograd的POA。每个16位宽的乘法器和加法器都可以拆分成int8格式的两个计算单元,所以int8的吞吐量是int16的两倍;MAC Cell的流水线深度为7个Cycle。
为了Physical Design Optimization,CMAC被分为两部分CMAC_A和CMAC_B,每个都有单独的CSB接口。
CACC
卷积累加器(CACC)是卷积流水线在CMAC之后的阶段,它用于累加CMAC模块的部分和,并在发送到SDP之前对结果进行舍入/饱和。它支持不同位宽的数据输入,对于INT16输入而言结果位宽为48位,对于INT8输入而言结果位宽为34位。CACC和SDP模块之间的数据位宽是32,所以在将结果发送给SDP之前需要执行一个舍入和饱和运算。
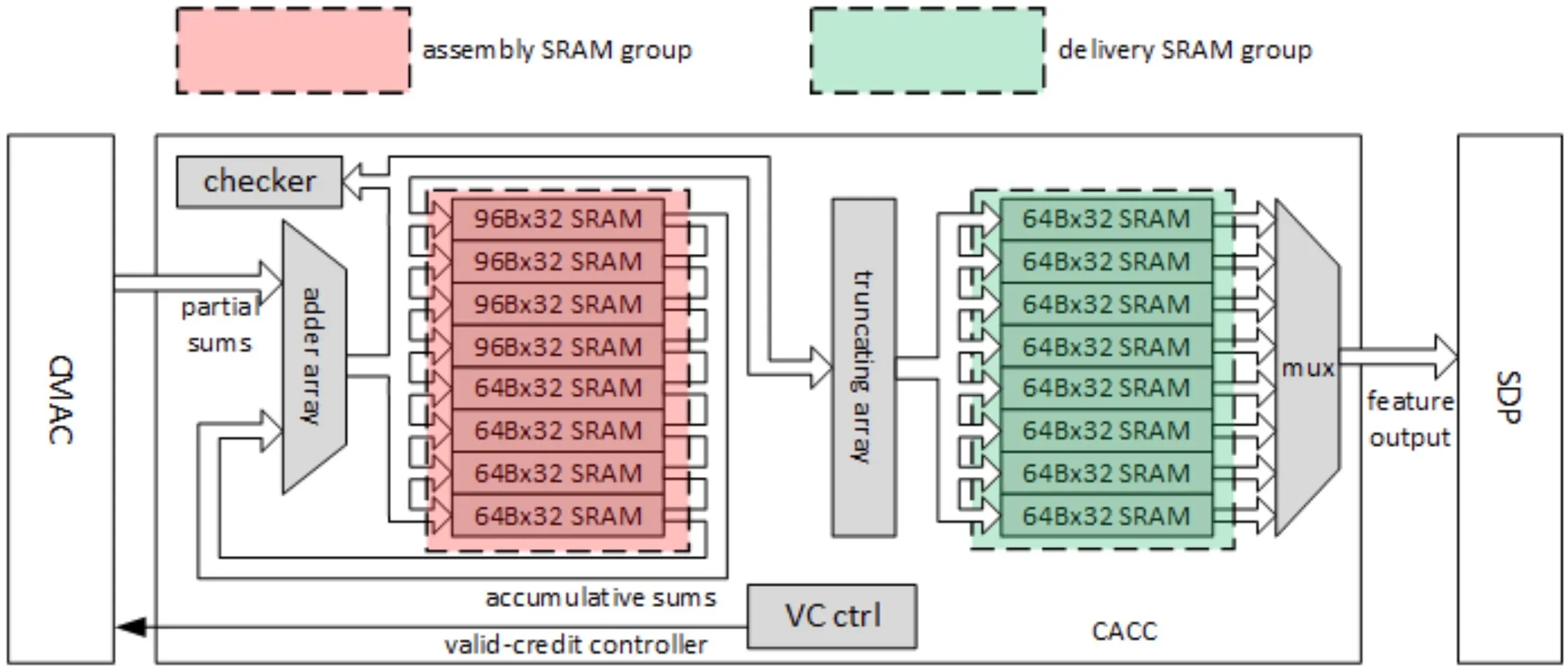
CACC中的组件如图所示,工作流程主要如下:
- 从assembly SRAM中预取累加和;
- 当CMAC的部分和到达时,将它们与累加和一起发送到adder array;如果部分和来自第一个stripe operation,则累积和应为0;
- 从adder array的输出端收集新的累加和;
- 存储到assembly SRAM中;
- 在stripe operation中重复step1~step3,直到一个channel operation完成;
- 如果完成channel operation,加法器的输出将被舍入并饱和;
- 收集上一步的结果并将其存储到delivery SRAM中;
- 从delivery SRAM中加载结果并将它们发送给SDP;
为支持Direct Convolution模式下的Multi-Batch选项,CACC在交付SRAM组中应用了data remapping功能;为了防止数据溢出,CACC使用相关协议来反压CSC模块。
SDP
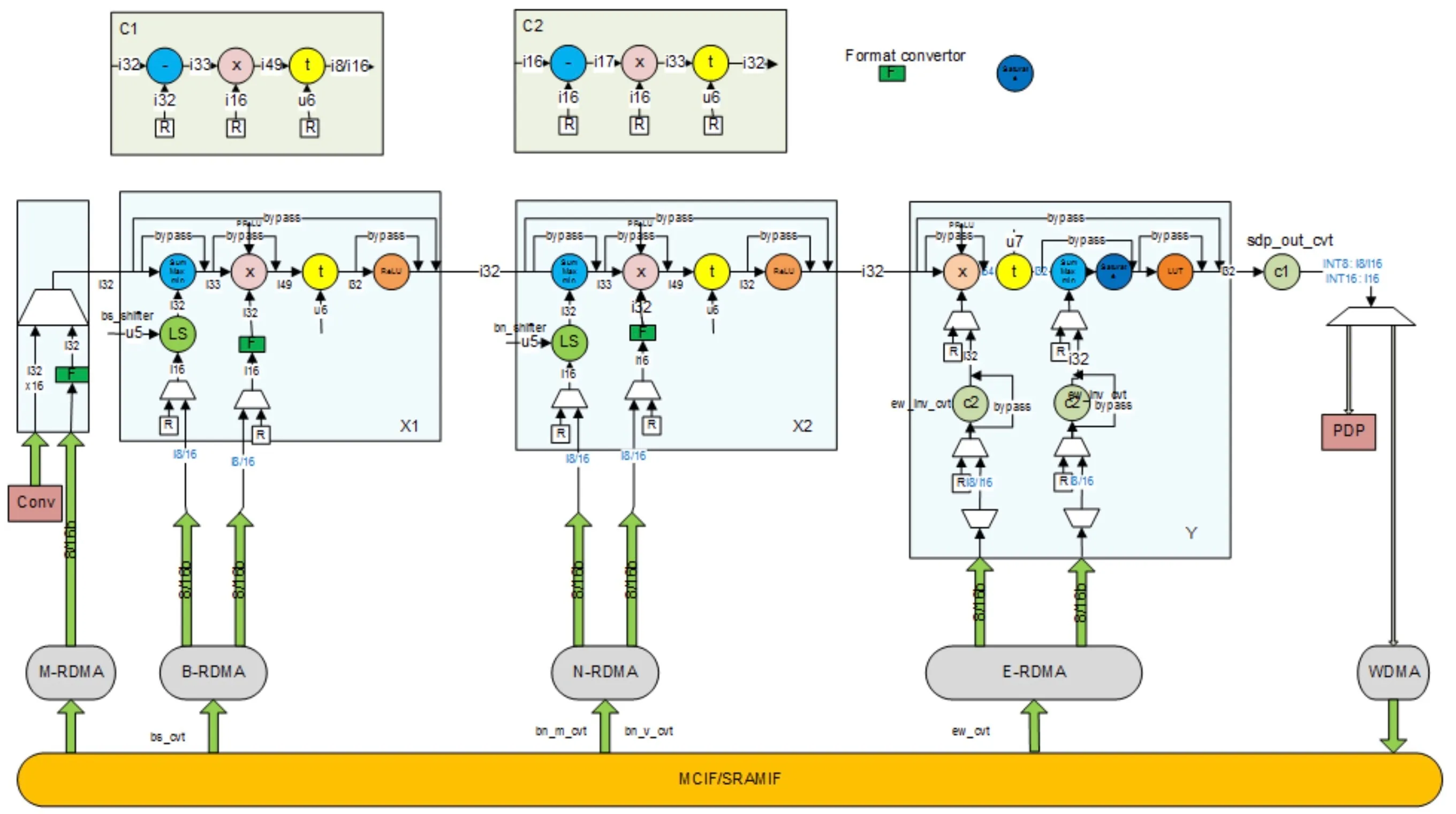
SDP是单点数据处理器,意在对单个数据元素级别执行后处理操作,主要完成以下的操作:
- Bias加法的公式为
y=x+bias,bias是一个预先训练的参数,可以是以下3种之一:如果整个data cube都是同一bias的话可以从寄存器获取;per-channel模式下,同一channel内bias共享;per-element模式下,不同的element的bias都不同。 - Non-Linear Function,包括ReLU、Sigmoid和双曲正切。ReLU可以通过硬件逻辑实现,Sigmoid和双曲正切函数是非线性函数,所以用查找表来实现;
- Batch Normalization:SDP支持使用给定的均值/标准方差参数进行批量归一化,参数是从训练中获得的,SDP还可以支持按层参数或者按通道参数进行批量归一化操作;
- Element-Wise Layer:它指两个具有相同W、H和C参数的特征数据立方体之间的一种操作。这两个W×H×C特征数据立方体进行元素加法、乘法、或MAX/MIN比较操作,并输出一个W×H×C的特征数据立方体;
- PReLU Function,ReLU是将负值裁剪到0,而PReLU是将负值进行缩放;
- Format Conversion:NVDLA支持INT8、INT16和FP16精度,较低的精度可提供较高的性能,而较高的精度可提供更好的推理结果。
PDP
PDP主要沿宽×高的平面执行操作,PDP模块旨在完成池化层,支持MAX、MIN和AVERAGE池化操作。PDP单元接收来自SDP或者MCIF/SRAMIF的数据,并将数据发送给MCIF/SRAMIF。
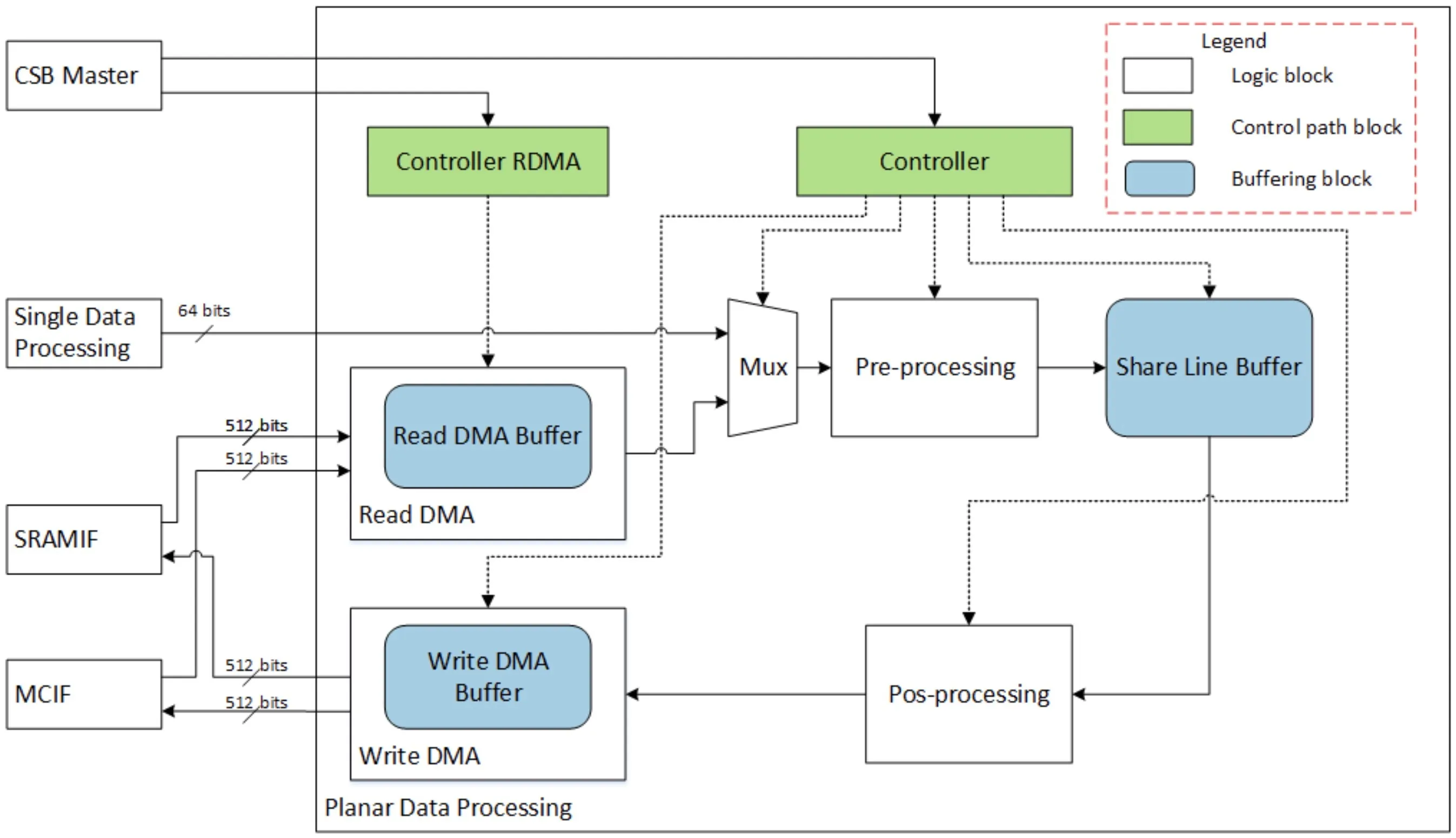
支持的尺寸如下:Pooling Kernel Size:1~8;Pooling Kernel Stride:1~16;
on-the-fly模式下输入数据直接从SDP获取,off-fly模式下输入数据从PDMA获取;
Pre-processing模块主要完成最大、最小操作以及部分和的求和操作;
Pos-processing模块主要针对Average Pooling进行相关的后处理操作,如果是MAX/MIN Pooling操作的话,那么Share Line Buffer存储的就是最终结果;如果是Average Pooling的话,需要取出Share Line Buffer中的数进行除法操作,并且为方便硬件实现将除法转换为乘法操作;
CDP
CDP模块旨在解决局部响应归一化层,LRN通过在通道方向上对局部输入区域进行归一化。CDP模块始终与其它处理子单元独立工作,它从PDMA接收输入数据并将输出数据发送回PDMA。
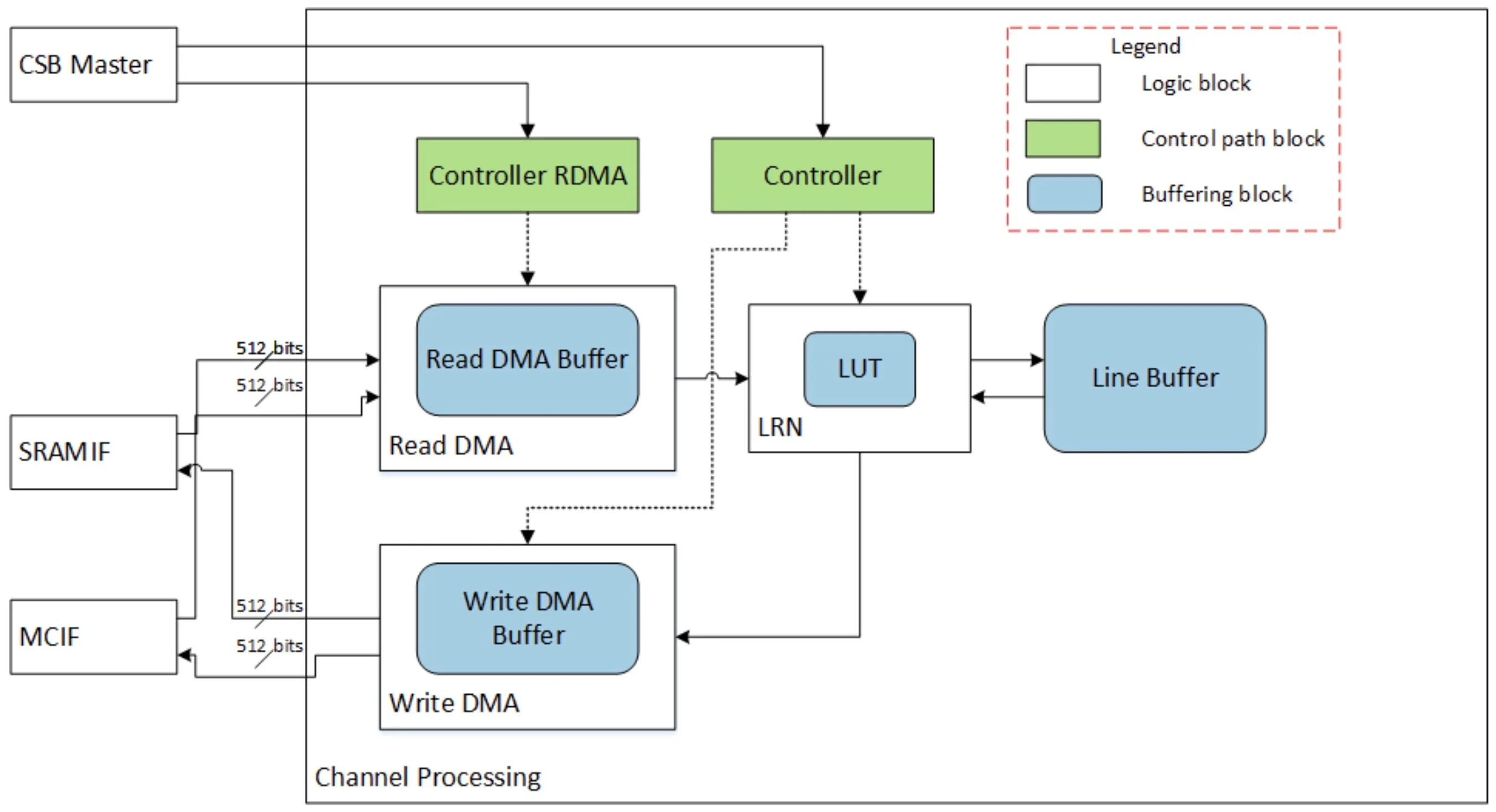
LRN的计算公式中涉及到除法和指数运算,使用硬件实现代价较大,所以内部用LUT实现功能。
RUBIK
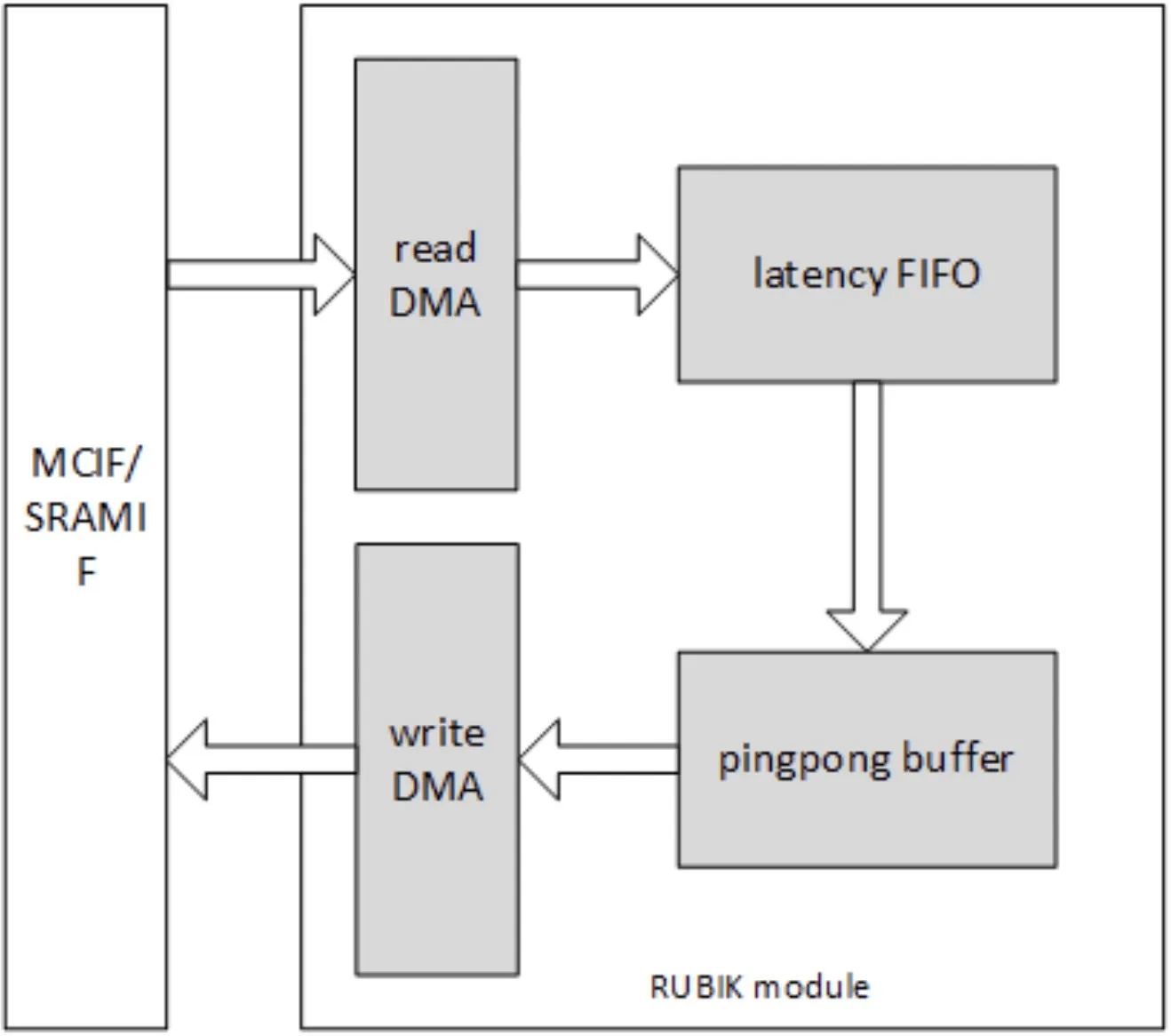
RUBIK的功能是转换数据的映射格式,主要有三种工作模式:
- contract data cube
- split feature data cube into multi-planar formats
- merge multi-planar formats to data cube
BDMA
NVDLA一般将输入图像和处理结果存储在外部DRAM中,但受限于DRAM的带宽和延迟,NVDLA不能提高MAC阵列的效率,所以NVDLA配置了一个到片上SRAM的辅助存储器接口。
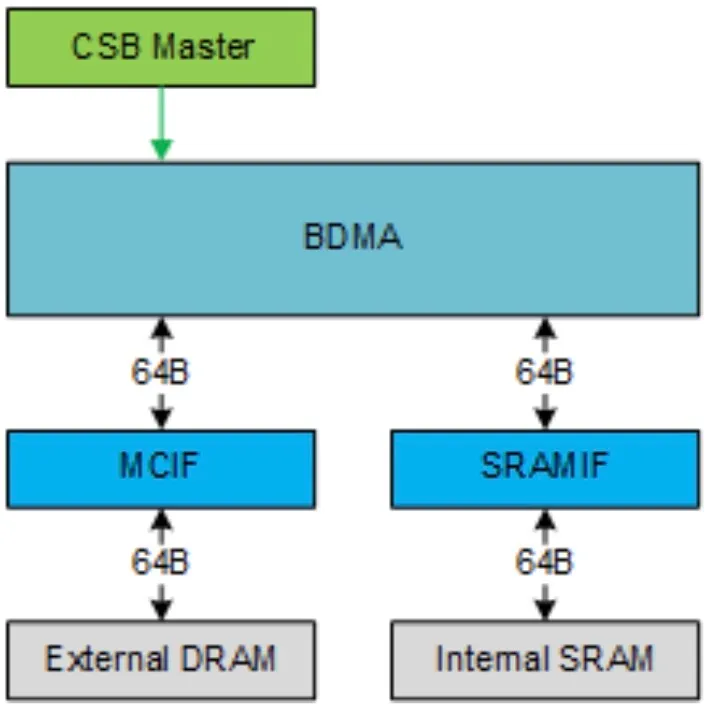
NVDLA使用BDMA来在外部DRAM和内部SRAM之间移动数据,有两个独立的路径,一个是从DRAM到SRAM,另一个是从SRAM到DRAM,两个方向不能同时工作。同时BDMA还可以将数据从DRAM移动到DRAM,或者从SRAM移动到SRAM。
两个接口的数据位宽均为512位,最大突发长度为4。
MCIF&SRAMIF
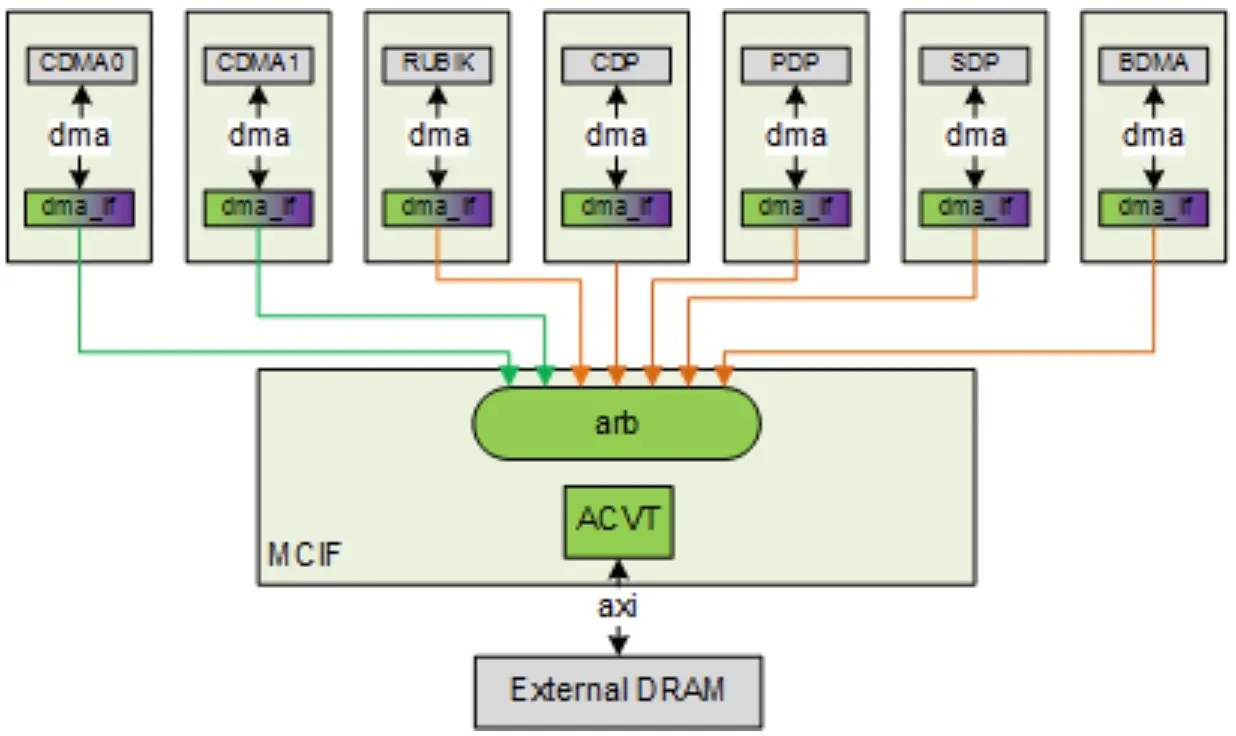
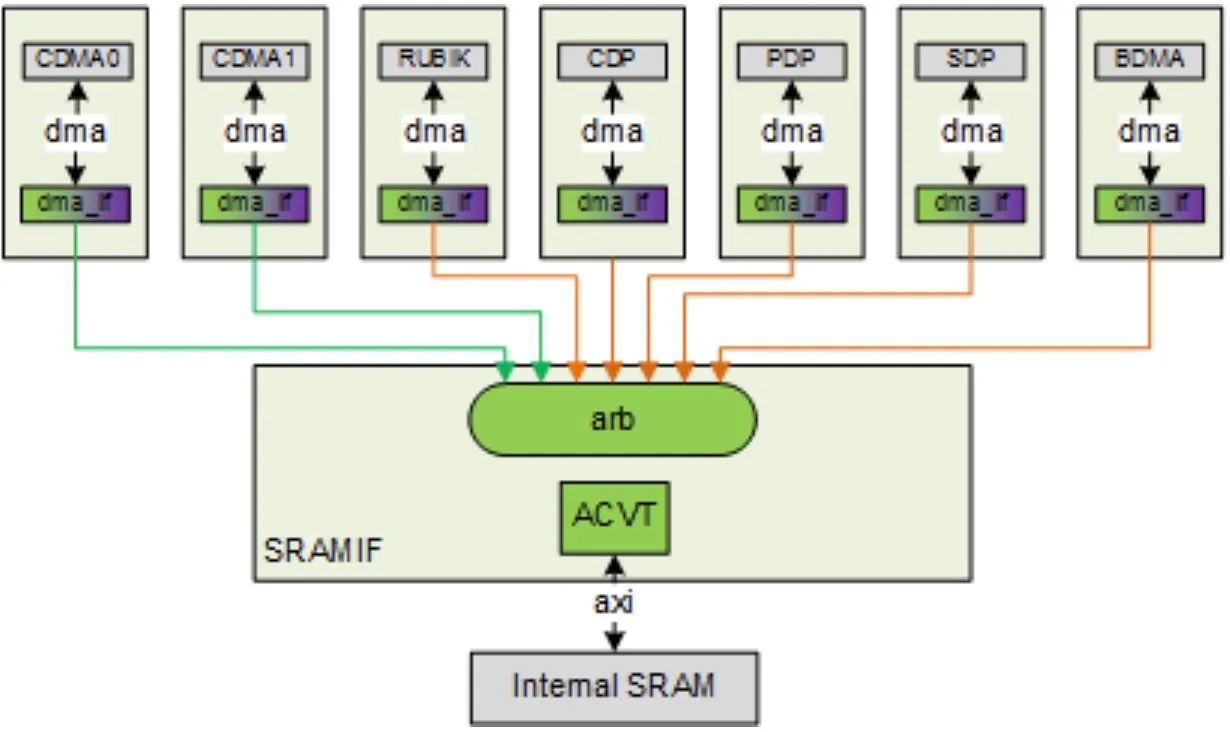
MCIF用于仲裁多个内部子模块的请求,并转换为AXI协议来连接到外部DRAM。MCIF是同时支持读写通道的仲裁的,但有些NVDLA的子模块只有读请求,如图中的CDMA0和CDMA1只有读请求,其它5个接口均需要读写。
SRAMIF与MCIF接口功能类似,但预计总线延迟更低。
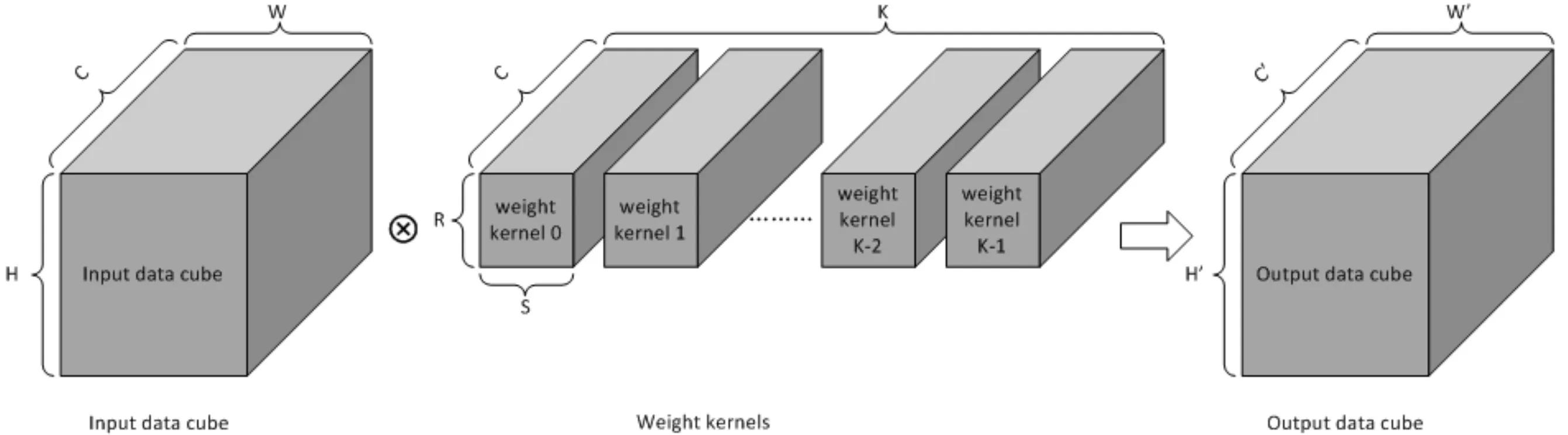
Convolution in NVDLA
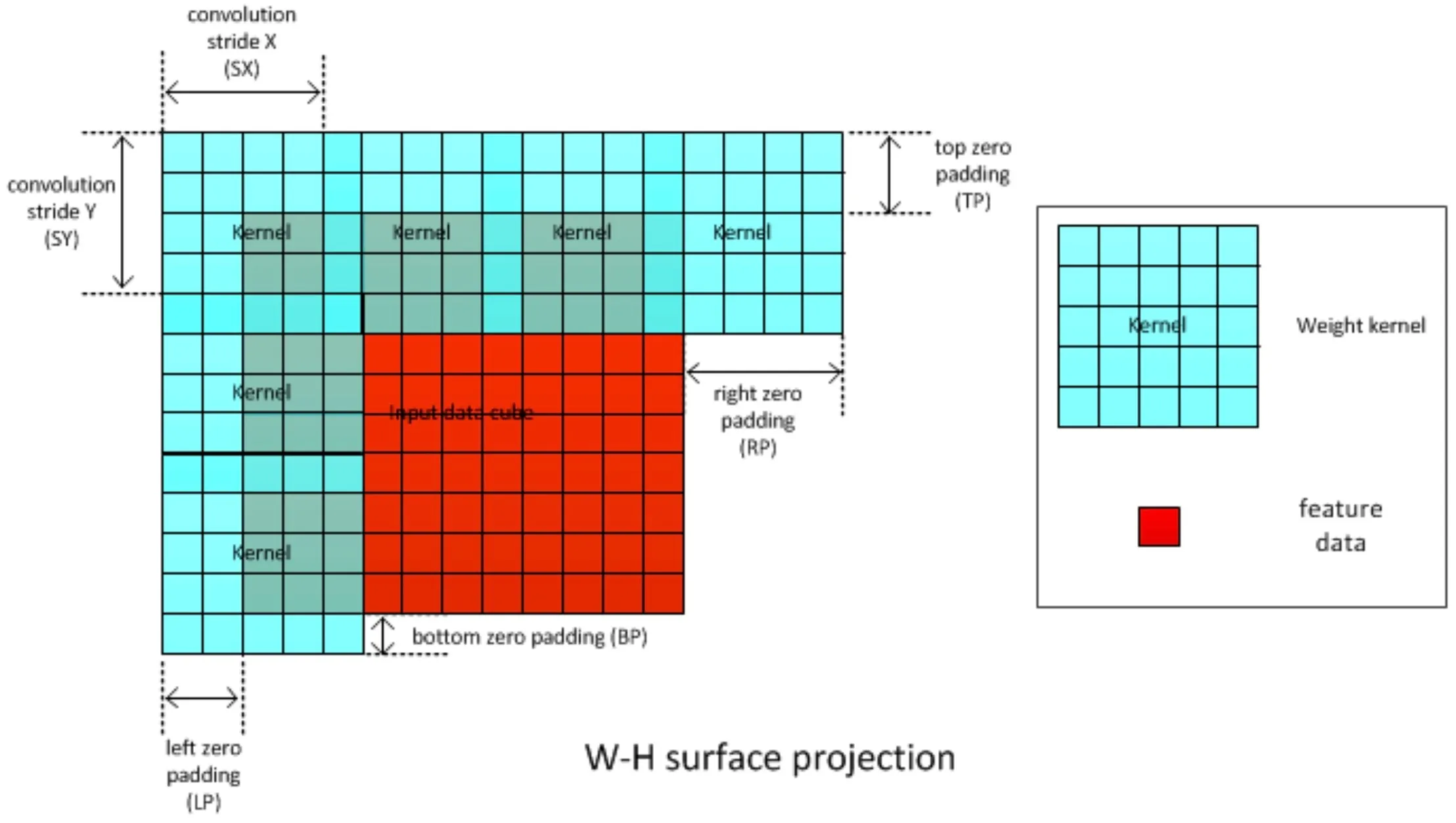
下面简单说一下NVDLA中直接卷积的流程。输入的Data Cube为W×H×C;共K个kernel,每个kernel的尺寸为S×R×C;输出的Data Cube尺寸为W’×H’×C’;其中W’和H’与Padding和Stride有关,C’与Kernel数量相等;
下图显示了Stride和Zero Padding的示意图,其中黑色虚线框出的是Padding之前的Feature Data;Kernel字母表示卷积核的中间位置,可以看到在X方向和Y方向上分别以SX和SY为距离进行步进;
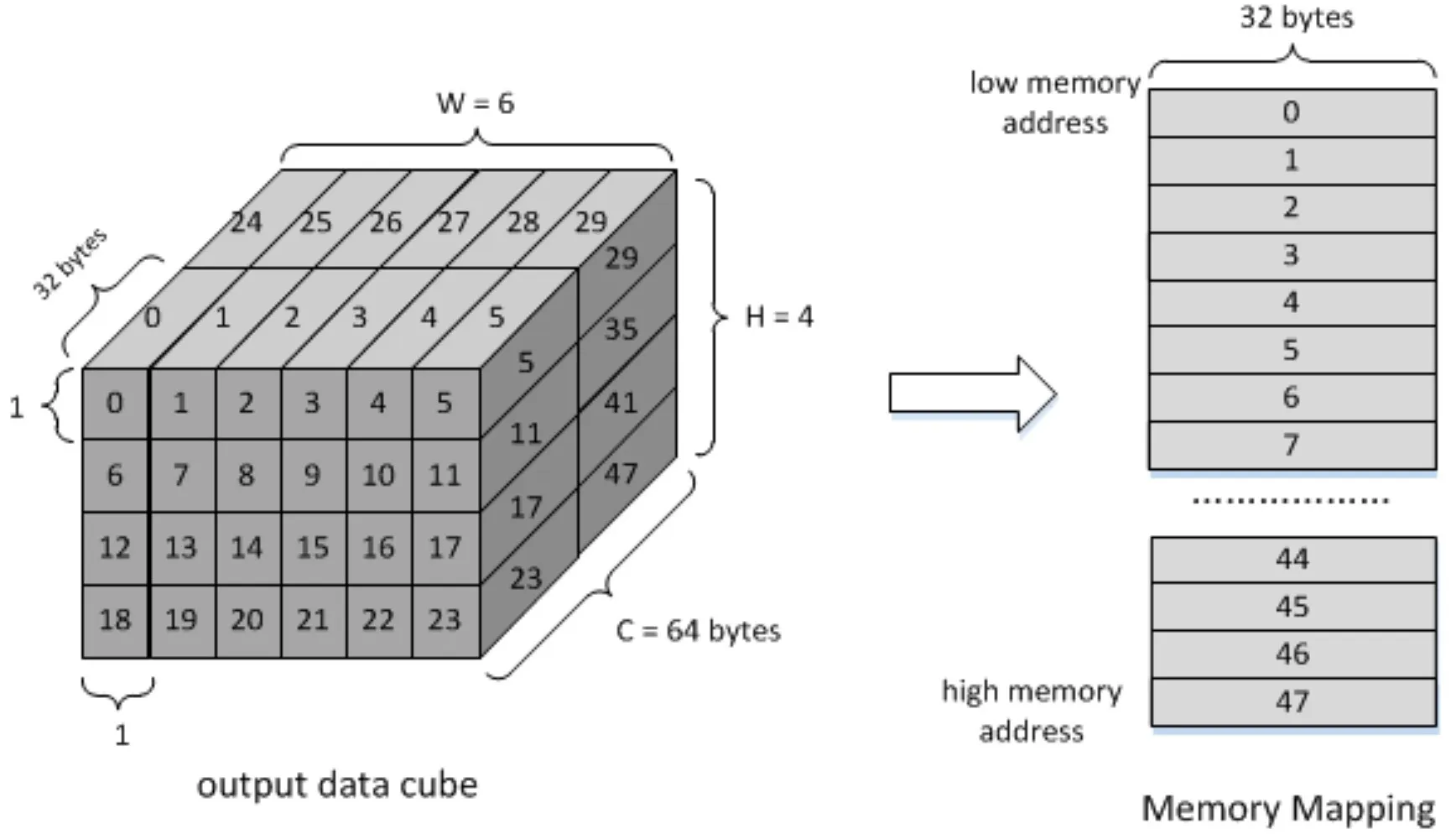
Data Format
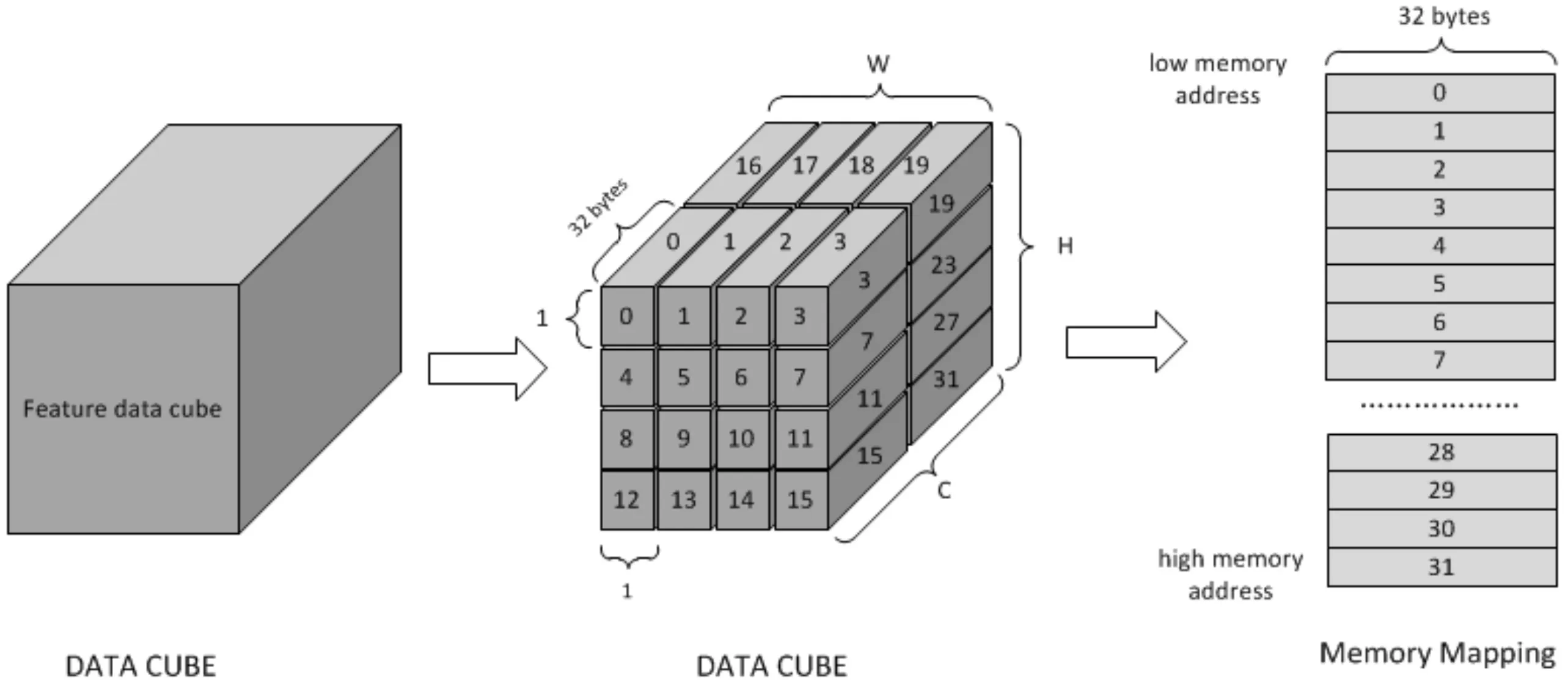
这张图显示了Direct Convolution模式下特征数据与权重的数据格式,特征数据以32Byte为单位,在W-H-C方向上进行扫描并对数据进行存储,如果原始特征数据不是C方向上的32字节对齐,则将数据添加到通道末尾;
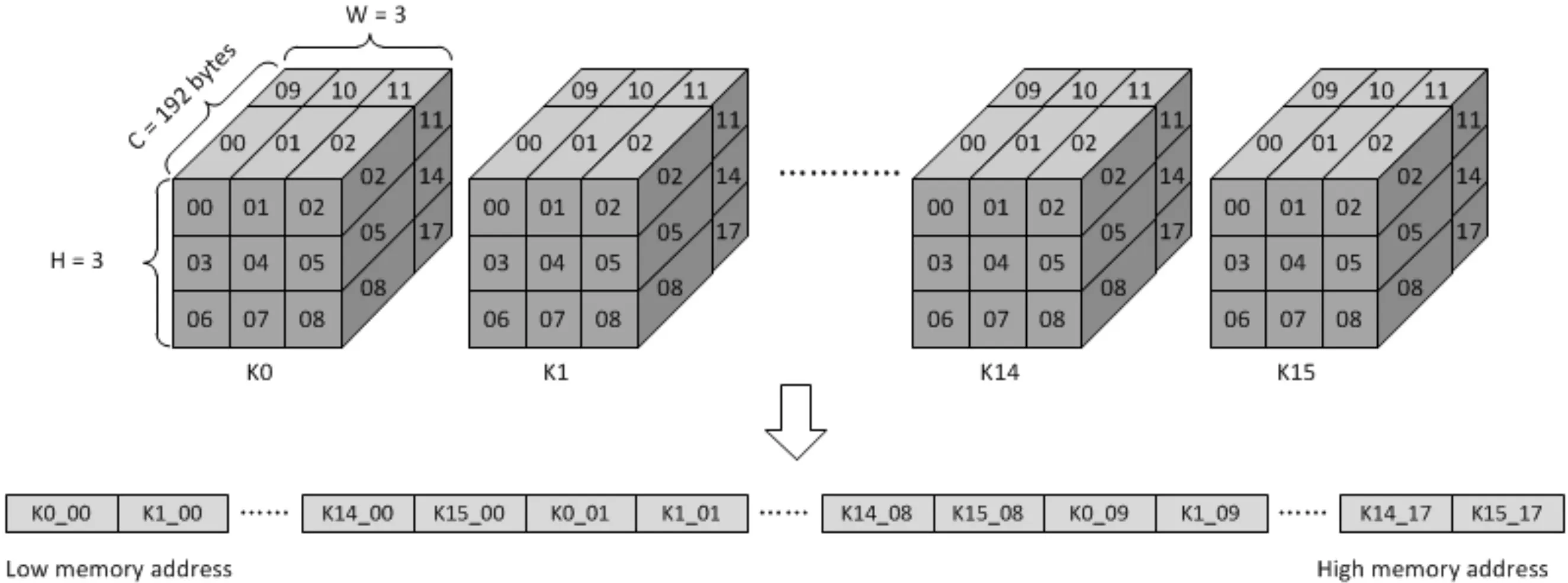
权重数据是在卷积操作之前很久就生成的,软件应将权重数据按DLA中的计算顺序进行映射。权重是在通道方向上以128Byte为单位进行划分,不足128Byte的话要进行一个补零操作,在C’-W-H-C方向上进行扫描并对数据进行存储。
Atomic Operation
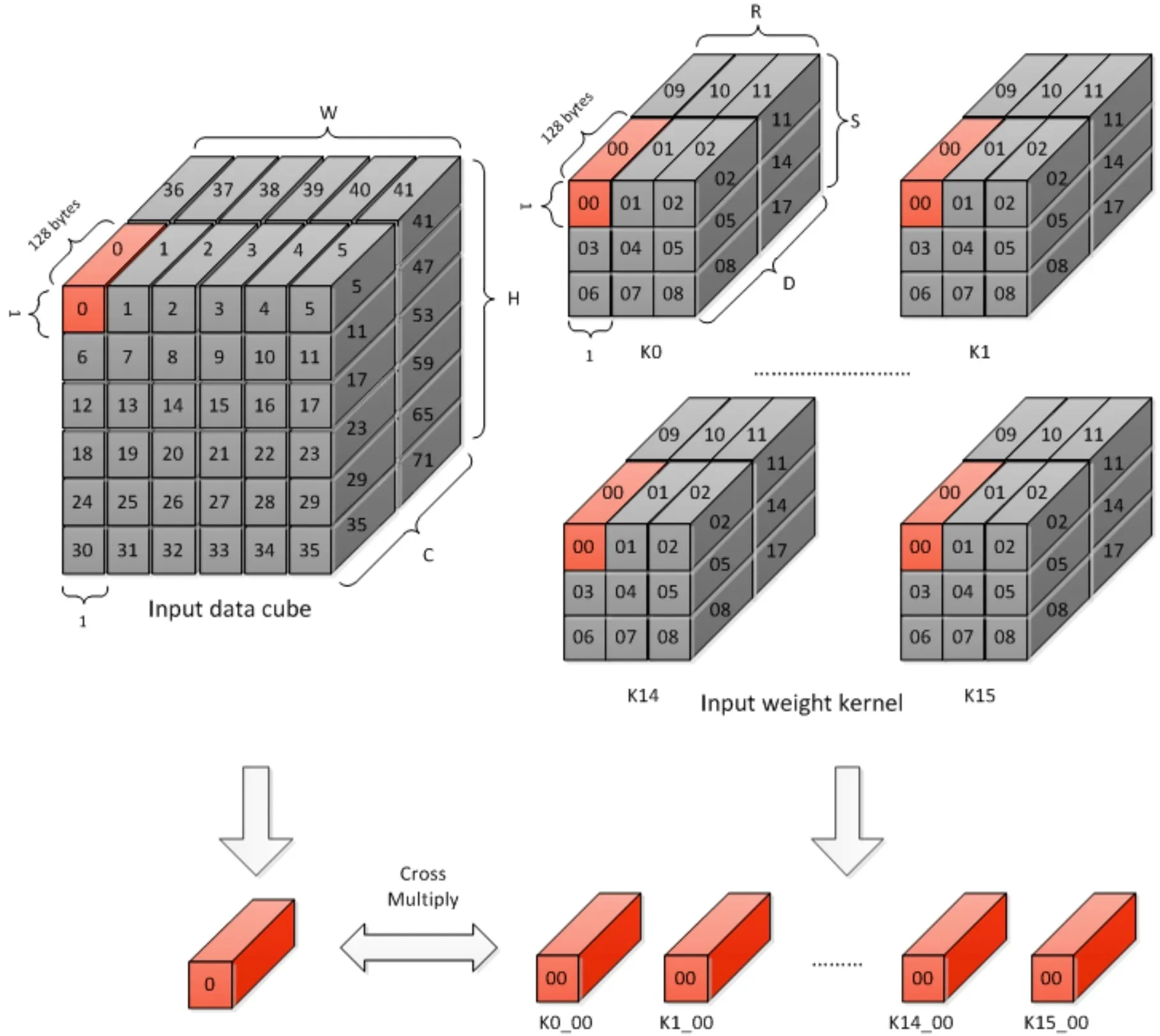
在一个原子操作中,每个MAC Cell都取一个1×1×64的weight cube(16bit)来与1×1×64的feature data做运算,完成64个数的乘加运算操作(64个Channel)。因为有16个MAC Cell,所以一次能并行计算16个kernel,MAC Cell乘加运算后的结果叫做部分和,所以每个Cycle我们可以得到16个部分和(partial sum)。得到的部分和被送往CACC模块进行累积和的计算。
Stripe Operation
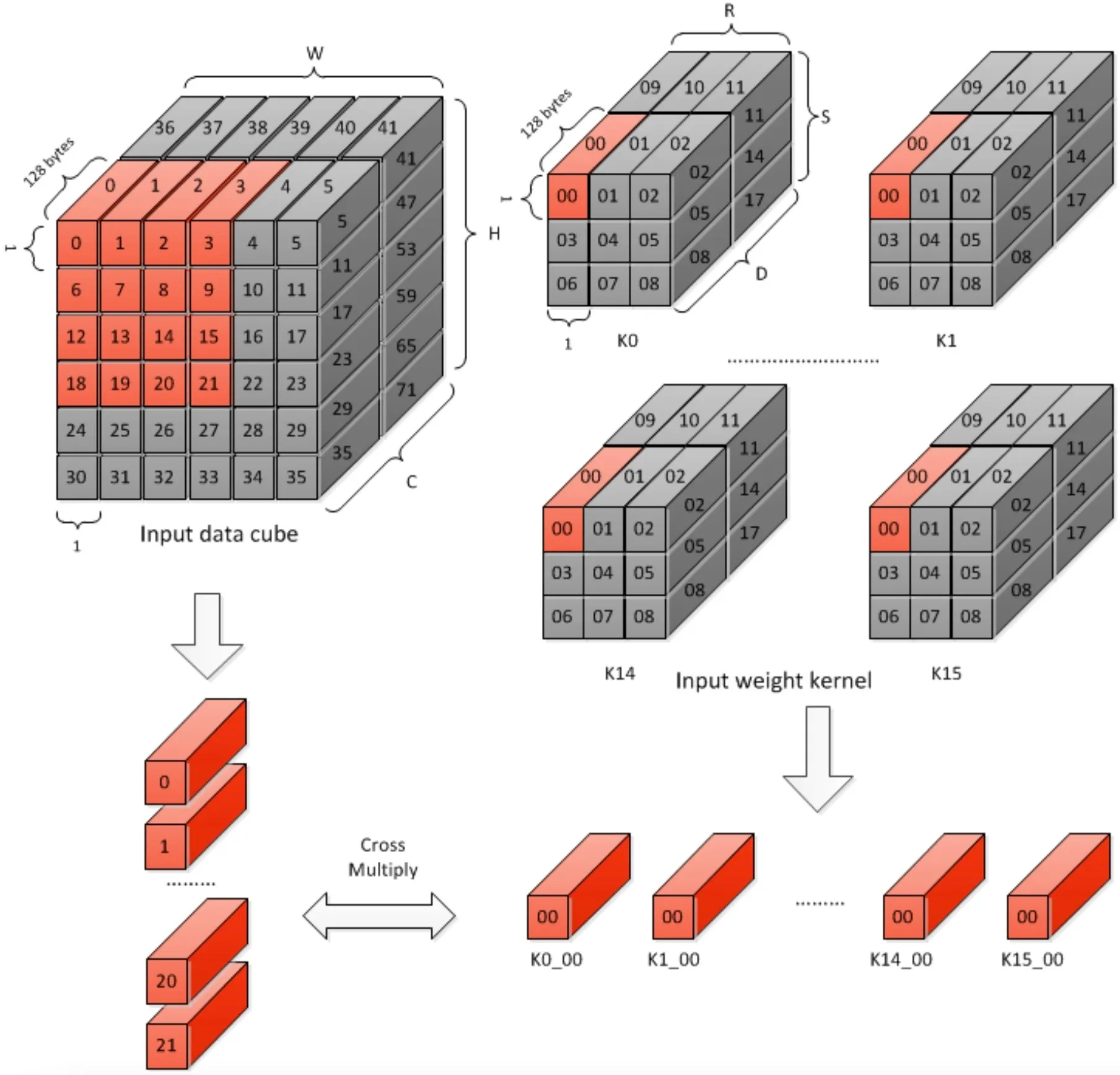
条带操作是原子操作的组合,在一次条带操作的过程中,MAC Cell中的权重数据保持不变,特征数据沿着input data cube滑动。(首先沿着W方向进行滑动)
由于条带操作MAC Cell中权重数据保持不变,所以一次条带操作中的部分和不能进行累加操作,因为它们来自不同的卷积核;这就是说需要在CACC模块对部分和进行缓存。
由于CACC模块的缓冲区受限,所以Stripe Operation的Length有上限,上限为32。同时Stripe Operation的Length也有下限,因为要更新下一次Stripe Operation的权重数据至少要16个Cycle,所以下限为16。
即1次Stripe Operation=16~32次Atomic Operation,其中Weight Data不变,滑动Feature Data。
Block Operation
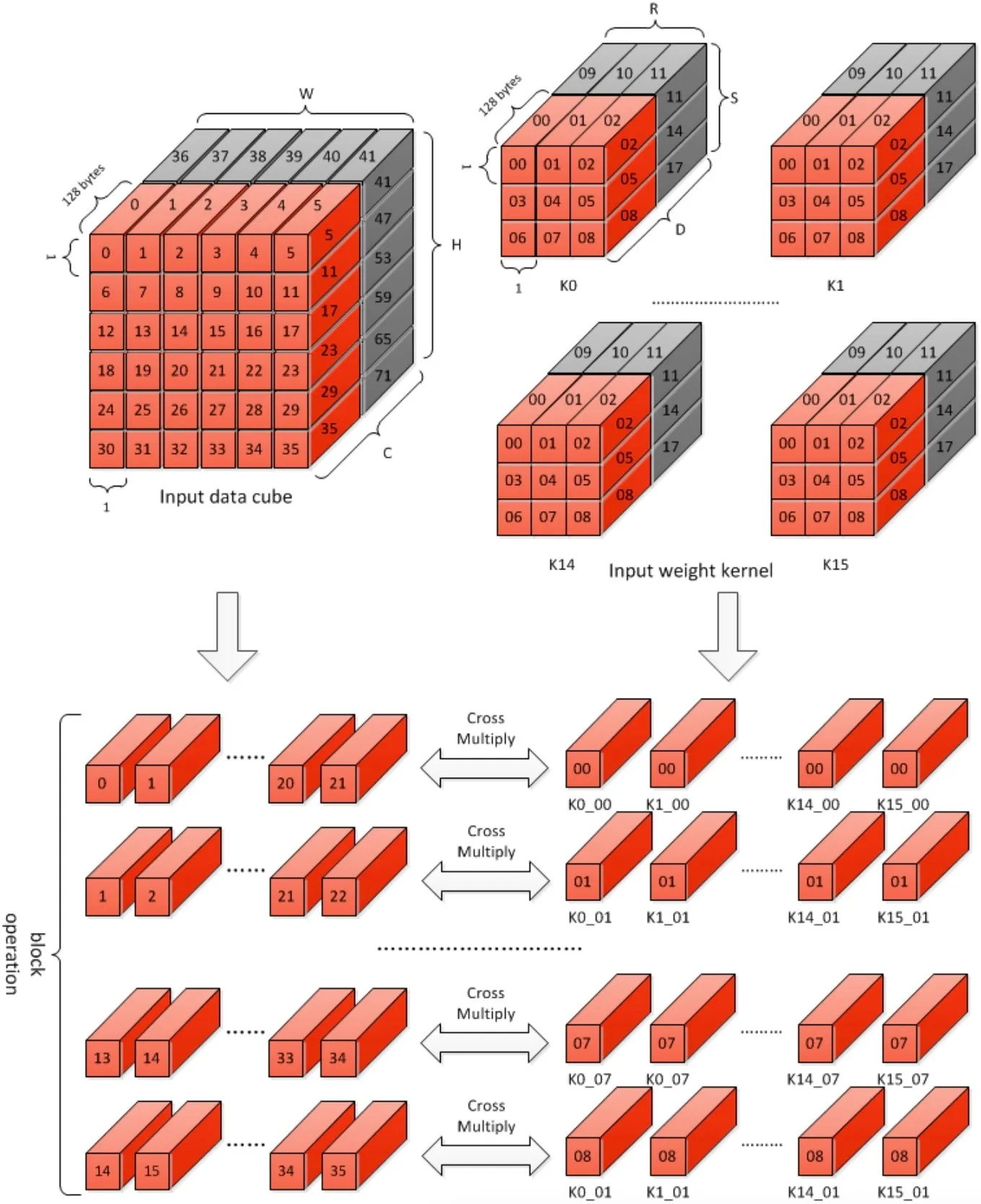
Block Operation是由一系列的Stripe Operation组成,次数为(Weight Width×Weight Height),每次Stripe Operation的部分和结果都被发送到CACC模块进行累加和的计算。
The partial sums from the same block operation are added together per stripe operation in the convolution accumulator.
累加和的计算公式如下:
在公式中,AS指accumulative sum,其中第一个和第二个求和应该是由CACC模块进行,第三个求和应该是MAC Cell进行。
Channel Operation
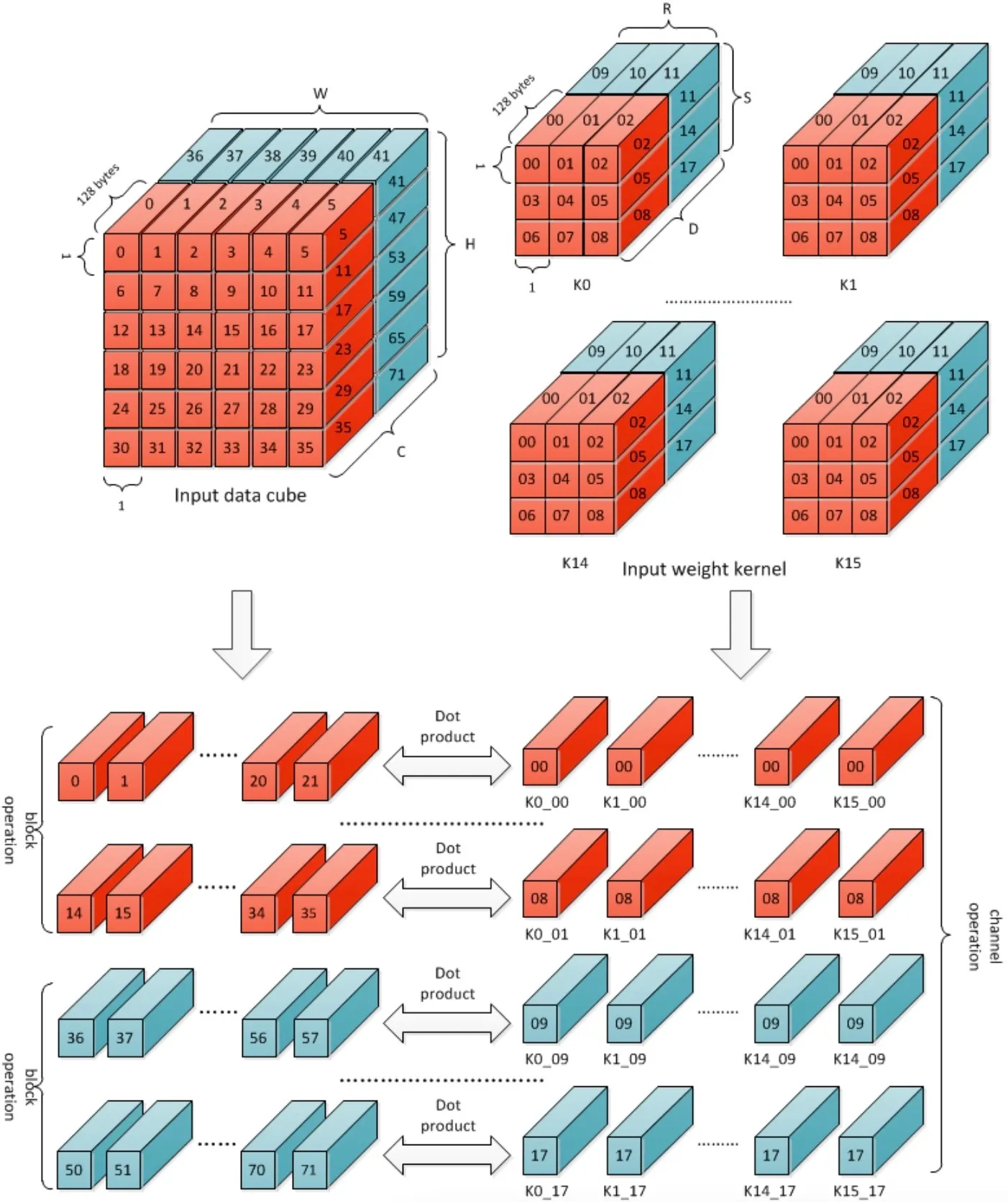
每次Block Operation完成64个kernel的运算,Channel Operation是一系列Block Operation的组合,次数共有(C+63)/64,完成Channel方向上的所有运算。在同一个Channel Operation中的部分和应该以卷积核为单位继续进行累加操作,在Channel Operation完成后,存储的累加和才是卷积的最终结果,才会从CACC模块中的assembly SRAM卸载到delivery SRAM,送给后续的处理模块。
Group Operation
Group Operation是Channel Operation的组合,需要重复(data_width*data_height)/(16~32)次。在Group Operation后,输出的数据尺寸为W×H×K',其中K’为一次Kernel Group中Kernel的数量,对于16-bit的数据而言为16个,对于8-bit的数据而言为32个。
Direct Convolution重复kernel_num/(16~32)次Group Operation即可完成卷积运算,每次的feature data都是相同的。
其它
权重压缩
- WMB:Weight Mask Bit,用一位标记来指示权重元素是否为0,1位与1个权重element对应;对于int16和fp16,1位代表2字节权重数据;对于int8,1位代表1个字节的权重数据;WMB始终是128Byte对齐,不足的补0。
- WGS:Weight Group Size,压缩后的权重组数据量大小,单位为Byte,位宽为32bit;
Multi-Batch Mode
NVDLA支持多批次模式来提高性能并降低带宽,特别是对于全连接层。全连接层的输出是1×1×C的data cube,也就是说FC层中的所有权重只使用一次,就是FC层的一个条带操作内只有一个原子操作,但流水线卷积还需要16个周期来为下一个原子操作加载权重,MAC的效率下降到6.25%。
多批次就是说同时处理多个输入的特征数据立方体,流水线卷积将为一组权重kernel获取多个输入数据立方体,这也改变了原子操作。来自不同输入数据立方体的1×1×64的cube一个一个交错加载以进行原子操作,然后条带操作包含多个批次的原子操作。由于权重在整个Stripe Operation中重复使用,因此可以把权重加载周期隐藏到处理流程中,提高了MAC的使用效率。
END
 微信
微信 支付宝
支付宝

