HDLBits答案(17)_Verilog有限状态机(4)
Verilog有限状态机(4)
前言
今天我们继续学习状态机的题目,这次会涉及两个重要的知识点:
- 独热编码状态机的组合逻辑设计
- PS/2接口的数据包解析器
PS/2接口是一种经典的键盘鼠标接口,虽然现在已经逐渐被USB取代,但它的协议设计非常经典,很适合用来学习状态机。
题库
题目1:One-hot FSM - 独热编码状态机
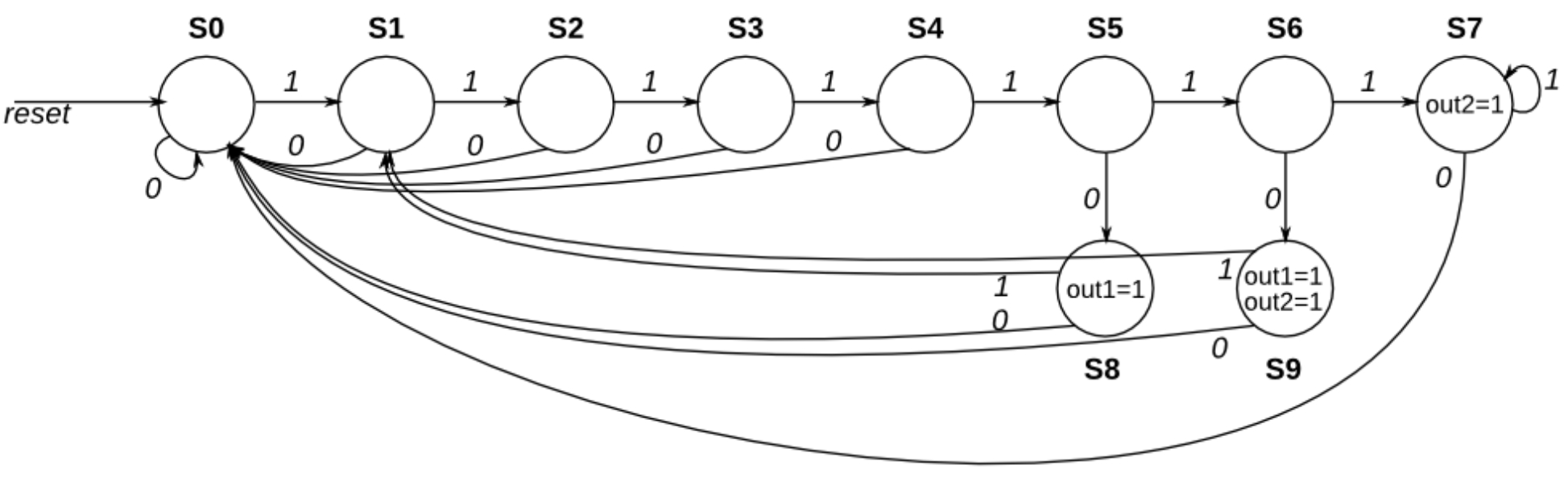
基础知识:什么是独热编码?
独热编码(One-hot encoding) 是一种特殊的状态编码方式,它的特点是:
- N个状态就需要N位寄存器
- 任意时刻,只有一位是1(热),其他都是0(冷)
- 比如有3个状态:S0=001, S1=010, S2=100
为什么叫”独热”? 想象一排灯泡,每次只有一个灯泡亮着,其他都是灭的,这就是”独热”。
独热编码的优点:
- 状态判断超级简单:只要看对应的位是不是1就行
- 组合逻辑通常更简单,速度更快
- 没有多个位同时变化的情况,不容易产生毛刺
独热编码的缺点:
- 占用更多的寄存器资源(状态越多越明显)
这就像给每个房间配一把专用钥匙,而不是用一串通用钥匙——开门更快,但钥匙更多。
题目理解
本题中,状态已经用独热编码的方式输入给我们了(state[9:0]),我们需要根据状态转移图推导出:
next_state[9:0]:下一状态的独热编码out1和out2:输出信号
Solution1:
1 | module top_module( |
代码要点
为什么可以这样写? 因为独热编码中,每个状态位是独立的!我们可以单独推导每一位的逻辑表达式:
next_state[S0]:哪些状态在输入为0时会转到S0next_state[S1]:哪些状态在输入为1时会转到S1- 以此类推…
这种写法看起来代码量不少,但逻辑非常清晰,综合器也能很好地优化。
题目2:PS/2 packet parser - PS/2数据包解析器(基础版)
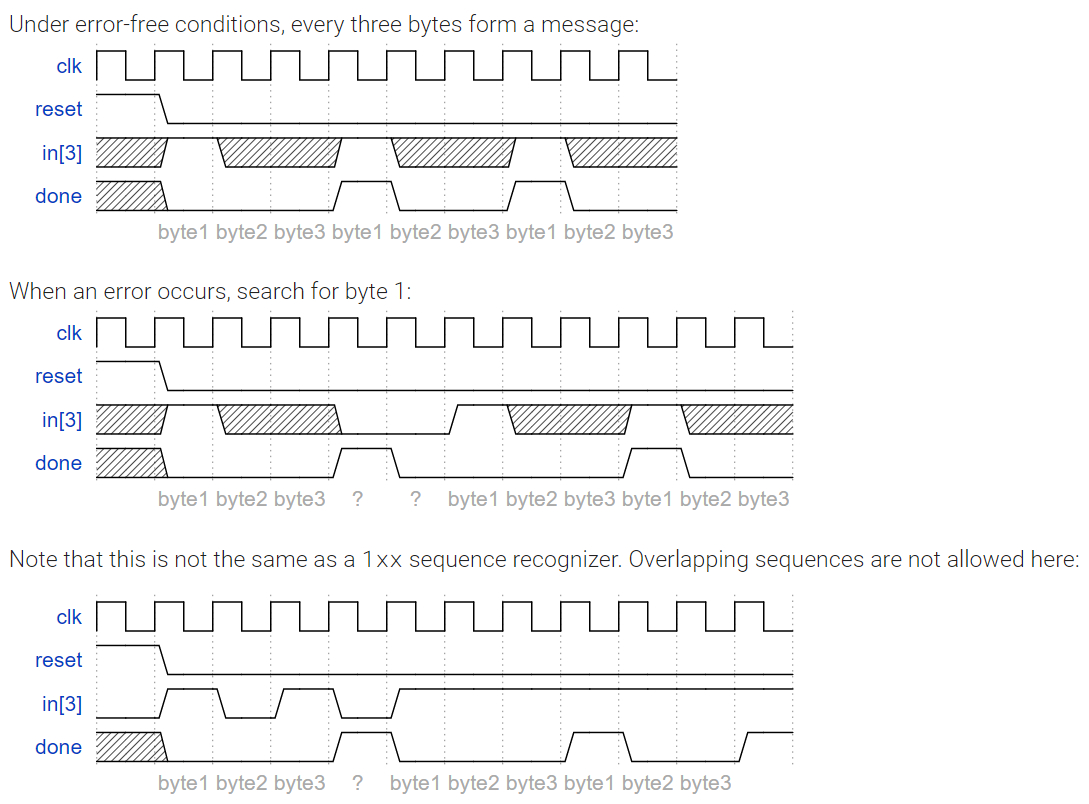
基础知识:PS/2协议简介
PS/2是一种用于键盘和鼠标的接口协议。数据是以字节为单位传输的,每个字节通常包含:
- 1个起始位(0)
- 8个数据位
- 1个停止位(1)
不过本题简化了协议,我们只需要检测数据包的开始。规则是:
- 当
in[3]为1时,表示新的数据包开始 - 我们需要接收3个字节(BYTE_FIRST → BYTE_SECOND → BYTE_THIRD)
- 不允许重叠检测:接收完3个字节后,要等下一个
in[3]=1才能开始新的包
题目理解
这个状态机的工作流程如下:
- WAIT状态:等待
in[3]=1(数据包开始) - BYTE_FIRST状态:接收第1个字节
- BYTE_SECOND状态:接收第2个字节
- BYTE_THIRD状态:接收第3个字节,此时
done=1 - 然后回到WAIT或BYTE_FIRST,取决于
in[3]的值
Solution2:
1 | module top_module( |
关键设计要点
注意状态机的复位状态! 复位时应该在WAIT状态,而不是BYTE_FIRST,因为我们要先等待数据包开始。
题目3:PS/2 packet parser and datapath - PS/2数据包解析器(数据通路版)
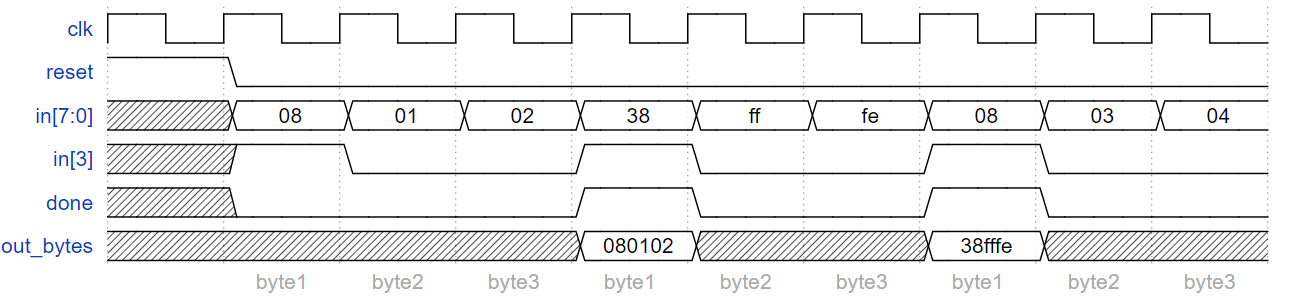
题目理解
这道题在上一题的基础上增加了数据输出功能:
- 当
done=1时,输出完整的24bit数据out_bytes[23:0] - 这24bit由3个字节组成:
- 高8位:第1个接收到的字节
- 中8位:第2个接收到的字节
- 低8位:第3个接收到的字节
所以我们需要数据寄存器来暂存接收到的字节!
Solution3:
1 | module top_module( |
关键设计技巧:用next_state提前捕获数据
注意看数据通路那段代码,我们用的是next_state而不是state!为什么?
因为状态在时钟边沿更新:
- 如果用
state判断:状态更新的那个周期,我们还在用旧状态判断,会错过数据 - 如果用
next_state判断:我们可以提前知道下一状态是什么,刚好在正确的周期捕获数据
这是一个非常实用的技巧!就像接棒赛跑,你要提前知道下一个接棒的人是谁,而不是等他已经站在那里了才准备。
入门者避坑指南
在做PS/2解析器这类题目时,初学者最容易犯以下错误:
错误1:用state判断数据捕获,错过一个周期
错误表现:1
2
3
4
5
6// 用state判断,会晚一个周期!
always @(posedge clk) begin
if (state == BYTE_SECOND) begin
out_bytes_reg[23:16] <= in;
end
end
错误原因:
- 状态在时钟边沿更新
- 当
state变成BYTE_SECOND时,已经是下一个周期了 - 数据应该在前一个周期就捕获
正确做法:1
2
3
4
5
6// 用next_state判断,刚好捕获
always @(posedge clk) begin
if (next_state == BYTE_SECOND) begin
out_bytes_reg[23:16] <= in;
end
end
错误2:状态转移顺序混乱
错误表现:1
2
3
4
5
6
7
8BYTE_THIRD: begin
next_state = DONE;
end
DONE: begin
if (in[3]) begin
next_state = BYTE_FIRST; // 错了!应该直接去BYTE_SECOND
end
end
错误原因:
- 没有仔细看时序图
- 当在DONE状态时,如果
in[3]=1,表示新包的第1个字节已经在接收了! - 所以应该直接去BYTE_SECOND,跳过BYTE_FIRST
调试技巧:
- 画波形图!把
in、state、next_state都画出来 - 对照题目给的时序图,看看每个周期应该在什么状态
错误3:复位状态选错
错误表现:1
2
3
4
5
6
7always @(posedge clk) begin
if (reset) begin
state <= BYTE_FIRST; // 有些题目是对的,但不一定全对
end else begin
state <= next_state;
end
end
错误原因:
- 不同的题目,复位状态可能不同
- 要仔细看题目要求:复位后应该在哪个状态?
正确做法:
- 看题目描述和时序图,确定复位状态
- 题目2中复位应该在WAIT
- 题目3中复位应该在BYTE_FIRST
- 不要想当然!
错误4:数据位序搞反
错误表现:1
2
3
4
5
6
7
8// 位序搞反了
if (next_state == BYTE_SECOND) begin
out_bytes_reg[7:0] <= in; // 第1个字节存到低8位
end else if (next_state == BYTE_THIRD) begin
out_bytes_reg[15:8] <= in;
end else if (next_state == DONE) begin
out_bytes_reg[23:16] <= in; // 第3个字节存到高8位
end
错误原因:
- 题目通常会明确说明字节顺序
- 仔细看题目:”高8位、中8位、低8位分别从in[3]为1开始计起”
正确做法:
- 用笔在纸上画一下:第1个字节 → 哪里?第2个?第3个?
- 确认清楚再写代码
错误5:独热编码状态机用case语句
错误表现:1
2
3
4
5
6
7
8// 独热编码却用case(state)
always @(*) begin
case (state)
10'b0000000001: next_state[S0] = 1; // 太麻烦了!
10'b0000000010: next_state[S1] = 1;
// ... 要写10个case!
endcase
end
错误原因:
- 独热编码不需要用case语句
- 单独推导每一位的逻辑表达式更清晰
正确做法:1
2
3
4// 单独推导每一位
assign next_state[S0] = ~in & (...);
assign next_state[S1] = in & (...);
// ...
小结
今天我们学习了三个重要的状态机题目,主要收获有:
独热编码状态机:利用每个状态位独立的特性,可以单独推导每一位的逻辑表达式,代码清晰,速度快
PS/2协议解析器:一个典型的协议解析状态机应用,从简单到复杂,逐步增加功能
数据通路设计:当需要暂存数据时,要设计数据寄存器,并且用next_state判断来提前捕获数据,这是一个非常实用的技巧
复位状态的选择:不同的题目复位状态可能不同,一定要仔细看题目要求
作为一名通信IC设计师,笔者想说:协议解析是通信芯片设计中最常见的任务之一,从UART、SPI、I2C到PCIe、以太网,几乎所有接口都需要状态机来解析协议。学好这类题目,对未来的工程设计非常有帮助!
 微信
微信 支付宝
支付宝


