HDLBits答案(15)_Verilog有限状态机(2)
Verilog有限状态机(2)
前言
在有限状态机的设计中,状态编码方式的选择是一个非常重要的话题。今天我们继续学习状态机的几道经典习题,重点掌握独热编码(One-hot encoding)的设计方法,以及同步复位与异步复位的区别。这些都是实际工程中经常遇到的问题。
题库
题目6:One-hot FSM 组合逻辑实现
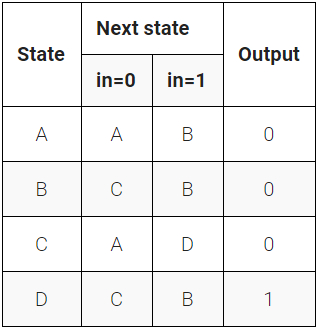
基础知识:状态编码方式
在深入题目之前,我们先了解一下常见的三种状态编码方式,它们各有优缺点:
二进制编码(Binary Encoding):
- 状态数为N时,使用log₂(N)位
- 优点:使用最少的寄存器资源
- 缺点:组合逻辑通常更复杂,多个位同时变化可能产生毛刺
格雷码(Gray Code):
- 相邻状态之间只有1位发生变化
- 优点:减少功耗,降低毛刺产生的概率
- 缺点:仅适用于状态按顺序转移的场景
独热编码(One-hot Encoding):
- 每个状态使用独立的一位,任意时刻只有一位为1
- 优点:状态判断简单(只需检查一位),组合逻辑更简单,速度更快
- 缺点:使用更多的寄存器资源(状态数N就需要N位)
这就像给每个人配一把专用钥匙(独热编码),还是用几把钥匙的组合(二进制编码)。前者开锁快但钥匙多,后者钥匙少但开锁需要尝试组合。
题目理解
本题要求使用独热编码的方式来实现状态转移逻辑。注意,这里的状态已经是独热编码的输入了,我们只需要推导组合逻辑方程即可。
Solution6:
1 | module top_module( |
本题要点
为什么独热编码可以这样写?
- 因为独热编码中,每个状态位是独立的
- 我们可以单独推导每一位的逻辑表达式
- 这样写的好处是代码可读性好,综合器优化效果也不错
题目7:异步复位的完整状态机
题目与上题相同,但这次我们要实现一个完整的状态机,包括状态寄存器,并且使用异步复位,复位到状态A。
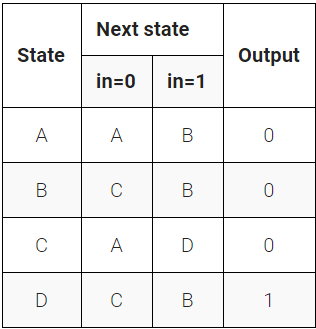
基础知识:异步复位 vs 同步复位
异步复位:
- 复位信号独立于时钟,只要复位信号有效,立即复位
- 优点:响应快,不依赖时钟,有些FPGA的触发器有专用异步复位端
- 缺点:复位信号的毛刺可能导致误复位,复位释放时需要考虑同步问题
同步复位:
- 复位信号只在时钟边沿有效时才起作用
- 优点:可以过滤掉复位信号上的毛刺,整个系统更同步
- 缺点:复位必须等待时钟边沿,可能需要更多逻辑资源
这就像电梯的紧急停止按钮:异步复位是按下立即停,同步复位是等到下一层才停。
Solution7:
1 | module top_module( |
代码结构说明
这里我们使用了经典的三段式状态机写法:
- 组合逻辑:根据当前状态和输入计算下一状态
- 时序逻辑:在时钟边沿更新状态(含复位逻辑)
- 输出逻辑:根据当前状态产生输出
题目8:同步复位的完整状态机
题目同上题,但将复位改为同步复位。
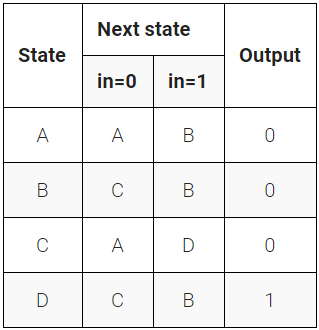
Solution8:
1 | module top_module( |
同步复位与异步复位的代码区别
注意看always块的敏感信号列表:
- 异步复位:
always @(posedge clk or posedge areset) - 同步复位:
always @(posedge clk)
这就是最关键的区别!同步复位只在时钟上升沿时才检查复位信号。
题目9:优先级编码器状态机
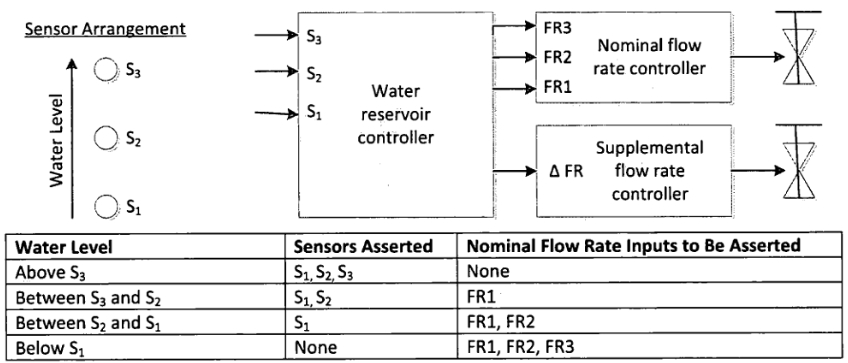
题目理解
这是一个典型的优先级编码器状态机设计问题。想象一个有多个用户请求使用资源的场景,不同用户有不同的优先级,高优先级用户可以抢占资源(或者在资源释放后优先获得)。
从题目可以看出,这是一个类似水位控制的状态机:
- s[3]优先级最高,s[2]次之,s[1]最低
- 状态A2、B1、B2、C1、C2、D1对应不同的水位
- 输出fr3、fr2、fr1表示哪些资源可用
- dfr表示方向(水位是上升还是下降)
Solution9:
1 | module top_module ( |
输出逻辑说明
使用位拼接操作{}可以让输出逻辑更简洁。这种写法在状态机输出较多时非常方便。
入门者避坑指南
在做这几道题的过程中,初学者经常会犯以下几个错误:
错误1:组合逻辑中使用阻塞赋值给reg
错误表现:1
2
3
4
5
6always @(*) begin
state = A; // 错误:直接给状态寄存器赋值
if (in) begin
state = B;
end
end
错误原因:
- 组合逻辑中不应该直接修改状态寄存器
- 状态更新应该在时序逻辑(always @(posedge clk))中完成
- 应该先用
next_state过渡
正确做法:1
2
3
4
5
6
7
8
9
10always @(*) begin
next_state = A; // 先给next_state赋值
if (in) begin
next_state = B;
end
end
always @(posedge clk) begin
state <= next_state; // 时序逻辑中更新状态
end
错误2:异步复位和同步复位混用敏感信号
错误表现:1
2
3
4
5
6
7
8// 同步复位却写成异步复位的敏感信号
always @(posedge clk or posedge reset) begin
if (reset) begin
state <= A;
end else begin
state <= next_state;
end
end
错误原因:
- 同步复位不需要把
reset放入敏感信号列表 - 这样写会让复位变成异步的
正确做法:1
2
3
4
5
6
7
8// 同步复位的正确写法
always @(posedge clk) begin
if (reset) begin
state <= A;
end else begin
state <= next_state;
end
end
错误3:组合逻辑没有default分支
错误表现:1
2
3
4
5
6
7
8always @(*) begin
case (state)
A: next_state = in ? B : A;
B: next_state = in ? B : C;
C: next_state = in ? D : A;
// 缺少default分支!
endcase
end
错误原因:
- 如果状态不是A、B、C,
next_state会保持之前的值 - 这会生成锁存器(latch),在时序电路中是不希望看到的
正确做法:1
2
3
4
5
6
7
8always @(*) begin
case (state)
A: next_state = in ? B : A;
B: next_state = in ? B : C;
C: next_state = in ? D : A;
default: next_state = A; // 加上default分支
endcase
end
或者更安全的做法,在case语句前先给next_state一个默认值:1
2
3
4
5
6
7
8
9always @(*) begin
next_state = A; // 先给默认值
case (state)
A: next_state = in ? B : A;
B: next_state = in ? B : C;
C: next_state = in ? D : A;
default: next_state = A;
endcase
end
错误4:参数未指定位宽
错误表现:1
2parameter A = 0; // 没有指定位宽
parameter B = 1;
错误原因:
- 未指定位宽的参数默认是32位
- 在状态机中通常只需要几位就够了
- 虽然综合器可能会优化,但指定位宽是更好的代码习惯
正确做法:1
2parameter A = 2'd0; // 指定2位宽度,值为0
parameter B = 2'd1;
调试技巧
- 画状态转移图:在写代码前先画好状态转移图,标清楚每个状态的输入输出
- 分模块测试:先测试状态转移是否正确,再测试输出逻辑
- 使用波形图:通过仿真工具查看波形,特别是在状态切换的时刻
- 打印信息:在仿真时可以用
$display打印状态变化,帮助调试
小结
今天我们学习了四道经典的状态机题目,重点掌握了:
- 三种状态编码方式:二进制编码、格雷码、独热编码,以及各自的优缺点和适用场景
- 异步复位与同步复位:它们的区别和代码写法
- 三段式状态机结构:组合逻辑、时序逻辑、输出逻辑分离,这是工程中推荐的写法
- 优先级编码器:一个实际的状态机应用案例
状态机是数字电路设计中非常重要的工具,多练习这些经典题目会让你收获很大!
 微信
微信 支付宝
支付宝


